Building an Image Analyzer with React and Amazon Rekognition

Introduction
In this tutorial, we'll create an Image Analyzer app using React and Amazon Rekognition. This app allows users to upload images and receive AI-powered analysis of the content, including object detection and text recognition. We'll focus on the technical implementation.
1: Setting Up the Project:
- First, create a new React project and install necessary dependencies:These commands set up a new React project and install:
npx create-react-app image-analyzer cd image-analyzer npm install aws-sdk axios react-dropzone - aws-sdk: For interacting with Amazon Rekognition
- axios: For making HTTP requests (though we won't use it directly in this tutorial)
- react-dropzone: For easy file uploads
2. Configuring AWS:
Create an AWS account and set up an IAM user with permissions for Amazon Rekognition. Then, create a file named aws-config.js in your src folder:
import AWS from 'aws-sdk';
AWS.config.update({
region: 'us-west-2', // Replace with your preferred region
credentials: new AWS.Credentials(
process.env.REACT_APP_AWS_ACCESS_KEY,
process.env.REACT_APP_AWS_SECRET_KEY
)
});
export const rekognition = new AWS.Rekognition();
This code configures the AWS SDK with your credentials. Make sure to create a `.env` file in your project root with your actual AWS credentials:
REACT_APP_AWS_ACCESS_KEY=your_access_key_here
REACT_APP_AWS_SECRET_KEY=your_secret_key_hereIMPORTANT: Never commit your .env file to version control!
3. Building the Main Component:
In App.js, create the main structure of the application:
import React, { useState } from 'react';
import { useDropzone } from 'react-dropzone';
import { rekognition } from './aws-config';
function App() {
const [image, setImage] = useState(null);
const [results, setResults] = useState(null);
const [loading, setLoading] = useState(false);
const onDrop = (acceptedFiles) => {
setImage(acceptedFiles[0]);
setResults(null);
};
const { getRootProps, getInputProps } = useDropzone({
onDrop,
accept: 'image/*',
multiple: false
});
// ... (analyzeImage function and JSX will be added later)
}
This sets up our component with three state variables:
- image: Stores the uploaded image file
- results: Stores the analysis results from Rekognition
- loading: Indicates whether an analysis is in progress
The onDrop function updates the image state when a file is uploaded and clears any previous results.
The useDropzone hook is configured to accept only image files and allow only single file uploads.
4. Implementing Image Analysis:
Add the analyzeImage function to perform the analysis using Amazon Rekognition:
const analyzeImage = async () => {
if (!image) return;
setLoading(true);
const reader = new FileReader();
reader.onload = async (event) => {
const imageBytes = new Uint8Array(event.target.result);
try {
const labelData = await rekognition.detectLabels({
Image: { Bytes: imageBytes },
MaxLabels: 10,
MinConfidence: 70
}).promise();
const textData = await rekognition.detectText({
Image: { Bytes: imageBytes }
}).promise();
setResults({ labels: labelData.Labels, text: textData.TextDetections });
} catch (error) {
console.error('Error analyzing image:', error);
alert('Error analyzing image. Please try again.');
} finally {
setLoading(false);
}
};
reader.readAsArrayBuffer(image);
};
This function:
- We define an asynchronous function named analyzeImage.
- It's asynchronous because we'll be performing operations that take time to complete.
Initial Checks:
- We first check if an image exists. If not, we immediately return from the function.
- We set a loading state to true, indicating that analysis has begun.
File Reading Setup:
- We create a new FileReader object. This is a built-in browser API for reading file contents.
- We define what should happen when the file is successfully loaded using the onload event handler.
File Reading Process:
- inside the onload handler, we create a Uint8Array from the loaded file data.
- Uint8Array is used because Amazon Rekognition expects image data as a byte array.
Rekognition API Calls:
- We make two separate calls to Amazon Rekognition services.
- a. detectLabels: This identifies objects, scenes, and activities in the image.
- b. detectText: This recognizes and extracts any text present in the image.
- Both calls are made using the promise() method to handle the asynchronous nature of the API.
detectLabels Configuration:
- We pass the image bytes to the API.
- We set a maximum of 10 labels to be returned.
- We set a minimum confidence threshold of 70% for the labels.
detectText Configuration:
- We only need to pass the image bytes for this call.
Handling Results:
- Once both API calls complete, we update our component's state with the results.
- We store the labels and text detections in an object.
Error Handling:
- If any error occurs during the API calls, we catch it.
- We log the error to the console for debugging.
- We display an alert to the user informing them of the error.
Cleanup:
- Whether the API calls succeed or fail, we set the loading state back to false.
Example return types:
labelData.Labels: An array of objects like [{Name: "Cat", Confidence: 99.15 }, ...]- textData.TextDetections: An array of objects like [{DetectedText: "Hello", Type: "LINE", Confidence: 98.43 }, ...]
Rendering the UI:
Add the JSX to render the application:
return (
<div className="App">
<h1>Image Analyzer</h1>
<div {...getRootProps()} className="dropzone">
<input {...getInputProps()} />
<p>Drag & drop an image here, or click to select one</p>
</div>
{image && (
<div>
<img
src={URL.createObjectURL(image)}
alt="Uploaded"
className="uploaded-image"
/>
<button onClick={analyzeImage} disabled={loading}>
{loading ? 'Analyzing...' : 'Analyze Image'}
</button>
</div>
)}
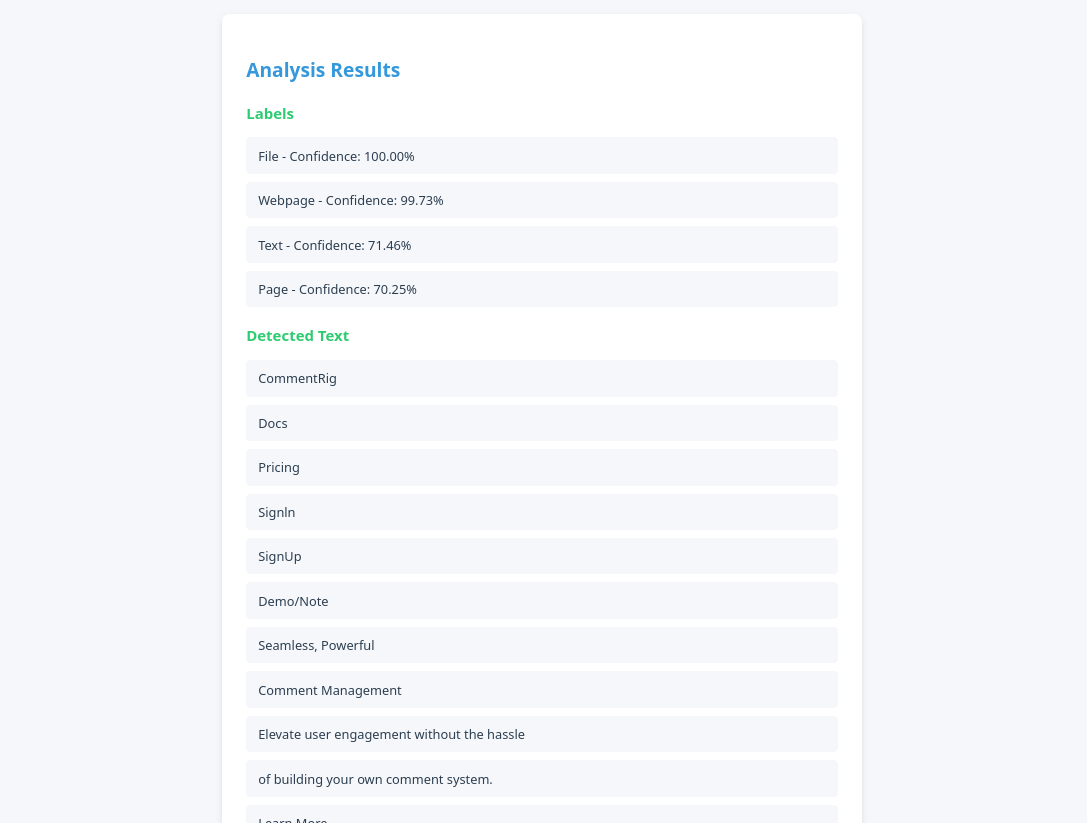
{results && (
<div className="results">
<h2>Analysis Results:</h2>
<h3>Labels:</h3>
<ul>
{results.labels.map((label, index) => (
<li key={index}>
{label.Name} - Confidence: {label.Confidence.toFixed(2)}%
</li>
))}
</ul>
<h3>Detected Text:</h3>
<ul>
{results.text
.filter(item => item.Type === 'LINE')
.map((textItem, index) => (
<li key={index}>{textItem.DetectedText}</li>
))}
</ul>
</div>
)}
</div>
);
This JSX:
- Renders a dropzone for image uploads
- Displays the uploaded image when available
- Provides an "Analyze" button that triggers the analysis
- Shows loading state during analysis
- Displays the analysis results, including detected labels and text
Styling the Application:
Add your CSS styles in App.css. We won't go into detail about our CSS.
Get full code here - GitHub - Abdulmumin1/aws-demos
Check out our previous tutorial - Building an Email Subscription and Broadcasting System with React and AWS SNS.
Conclusion:
You've now created a functional Image Analyzer using React and Amazon Rekognition. This app demonstrates:
- Integration of AWS services in a React application
- Handling file uploads with react-dropzone
- Asynchronous operations with loading states
- Displaying the data from the AI analysis
Next steps could include:
- Adding error handling for various scenarios (e.g., network errors, unsupported file types)
- Implementing more Rekognition features (e.g., face detection, celebrity recognition)
- Enhancing the UI with more detailed results or visualizations
- Adding the ability to analyze multiple images or compare images
Remember to handle your AWS credentials securely and consider implementing server-side code for production use to keep your AWS credentials private.
AWS Rekognition is really powerful and it offers a wide range of image and video analysis capabilities. Its key features include:
- Object and Scene Detection: Identifies thousands of objects, scenes, and activities in images and videos.
- Facial Analysis: Detects faces, analyzes facial attributes, and can perform facial comparison and recognition.
- Text in Image (OCR): Recognizes and extracts text from images, supporting multiple languages.
- Celebrity Recognition: Identifies celebrities in images and videos.
- Content Moderation: Detects inappropriate or offensive content in images and videos.
- Custom Labels: Allows you to train the service to recognize custom objects and scenes specific to your use case.
- Personal Protective Equipment (PPE) Detection: Identifies if individuals in images are wearing items like face covers, hand covers, and head covers.
- Video Analysis: Extends many of its image capabilities to video, including object detection, face recognition, and activity recognition.
- Streaming Video Analysis: Provides real-time analysis of streaming video.
- Facial Search: Allows searching and comparing faces across large collections of images.
Rekognition's capabilities make it suitable for a wide range of applications, including:
- Content moderation for social media platforms
- Automated image and video tagging for media organizations
- Security and surveillance systems
- User verification for financial services
- Inventory management in retail
- Sentiment analysis in customer service
The service is designed to be easy to use, requiring no machine learning expertise to get started. It's scalable, cost-effective (you only pay for the images and videos you analyze), and continuously improving as Amazon updates its underlying models.
However, it's important to note that, like all AI services, Rekognition has limitations. Its accuracy can vary depending on image quality, lighting conditions, and other factors. Also, the use of facial recognition technology raises privacy concerns that should be carefully considered in any implementation.
In our Image Analyzer app, we've only scratched the surface of what Rekognition can do. There's vast potential for expanding your app's capabilities by leveraging more of Rekognition's features.