Getting Started with DynamoDB - A Practical Approach
By abdulmumin yaqeen
on March 6, 2024

Getting Started with DynamoDB - A Practical Approach
What is DynamoDB?
AWS DynamoDB is a managed NoSQL database that is optimized for performance at scale. It's designed for high availability and to handle massive amounts of data.
DynamoDB being managed means that there is no need to manage the hardware, security patches and other related issues. Everything under the hood is nothing you need to care about.
One of DynamoDB's key features is its ability to automatically replicate data across multiple availability zones within a region, ensuring high availability and fault tolerance. It also offers flexible data modeling capabilities, allowing users to store structured, semi-structured, or unstructured data without the need for complex schema management.
DynamoDB is optimized for both read and write throughput, making it well-suited for use cases such as gaming, ad tech, IoT, mobile apps, and real-time analytics. Its performance is backed by SSD storage and a distributed architecture that can handle millions of requests per second.
With DynamoDB, you can benefit from features like encryption at rest, fine-grained access control using AWS Identity and Access Management (IAM), and integration with other AWS services such as AWS Lambda for serverless computing and Amazon Redshift for data warehousing.
Core concepts:
-
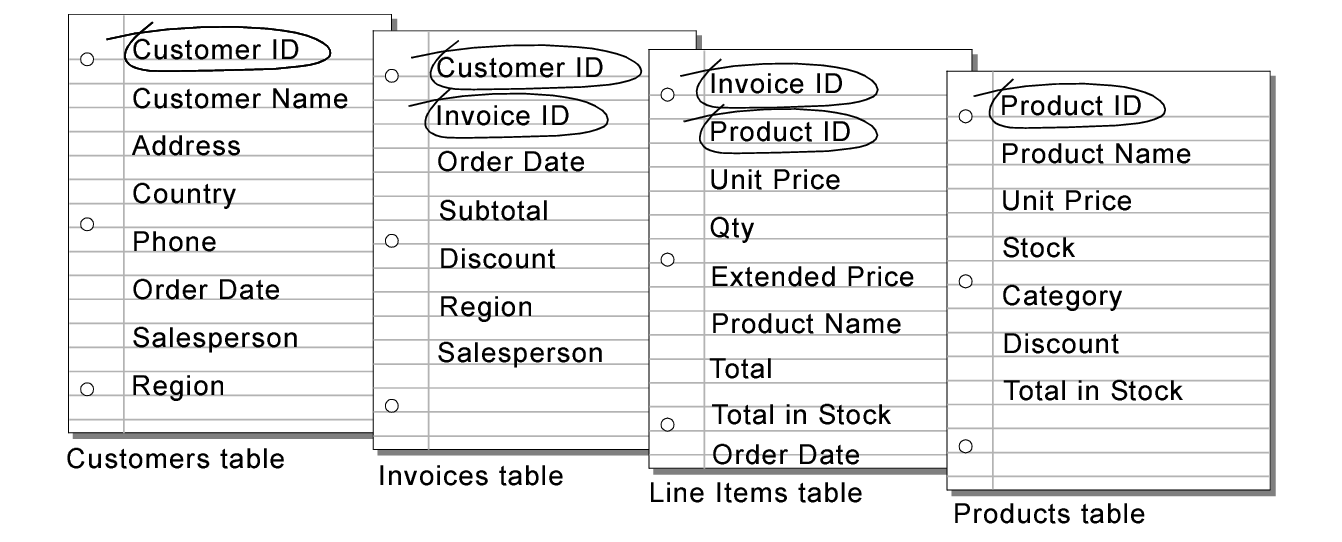
Tables: A table is a collection of items.

-
Items: A collection of Attributes, or key/ value paris.
-
Access Pattern:
An access pattern refers to the specific way in which data is queried or retrieved from the database. Access patterns are crucial for designing efficient DynamoDB tables and optimizing performance for different types of queries. Since DynamoDB is a NoSQL database, it doesn't support complex join operations like traditional relational databases. Instead, it relies on data modeling techniques that are tailored to the specific access patterns of an application.
Common access patterns in DynamoDB include:
- Single-item retrieval: Fetching a single item from the database using its primary key.
- Querying by a specific attribute: Retrieving multiple items that match a certain attribute value.
- Scan operations: Scanning through the entire table to find items that meet certain criteria.
- Secondary indexes: Creating secondary indexes to support queries based on attributes other than the primary key.
- Sparse indexes: Using sparse indexes to efficiently query for items where certain attributes may not exist.
- Time-series data: Storing time-series data and querying based on timestamps or date ranges.
Understanding the access patterns of an application is crucial for designing efficient table structures, choosing appropriate primary keys, and creating secondary indexes if needed. By optimizing access patterns, developers can ensure that DynamoDB tables perform well and scale effectively as the application grows.
Getting Started
We can jump to our AWS console, search and navigate to DynamoDB.

Keep in mind that every table we create is region specific.
We can now create a table.

Currently, we named the table “Products” and Partition key “productID”. we won’t be needing sort key, as our partition key will be unique.
A partition key is a primary key attribute that uniquely identifies each item in a DynamoDB table.
You can click on the Customize settings to view more options.

You can also turn on/off autoscaling, which will give you a dynamic or fixed capacity units.
With autoscaling enabled, DynamoDB continuously monitors your table's capacity utilization and adjusts provisioned capacity up or down as needed to maintain utilization at or close to your target value. This allows you to optimize cost by automatically scaling down capacity during periods of low traffic and scaling up during periods of high traffic, without the need for manual adjustments.
Autoscaling in DynamoDB can be configured to operate within specified minimum and maximum capacity limits, providing flexibility and control over resource allocation based on your application's requirements. It's a valuable feature for maintaining performance and cost efficiency in dynamic workloads.

Finally, you can use the create button.

The table takes a couple moments to create, and when it done, you can have a dashboard like this:

As mentioned earlier, DynamoDB tables are region specific, so the idea of global table create a replica of your table in other regions so users can access if faster.
Keep in mind you will be paying more for storage, and other resources provisioned.

To populate our table, you can use the “Explore table items” button.

Creating items;
You can use the form in the console, or JSON, or using the API.
Form console:

JSON view:

You can see in the JSON, we have the syntax as follows:
attribute_name: {"attribute_type": "attribute_value"}
In DynamoDB, the following attribute types are available:
- String (S): This type represents a Unicode string. The maximum length for a string attribute value is 400 KB.
- Number (N): This type represents a numeric value. Numbers can be positive, negative, or zero. Numbers are Unicode with a variable length, meaning that the maximum length of a number is constrained by the maximum item size limit. However, the number type itself doesn't have a specific size limit.
- Binary (B): This type represents a binary data (byte array). Binary attributes are useful for storing non-Unicode text, images, compressed data, and other types of binary data. The maximum size for a binary attribute value is 400 KB.
- Boolean (BOOL): This type represents a Boolean value, either true or false.
- Null (NULL): This type represents a null value.
- String Set (SS): This type represents a set of string values. Each string set can have multiple string values, but each value must be unique within the set. The maximum size for a string set is 400 KB.
- Number Set (NS): This type represents a set of numeric values. Each number set can have multiple numeric values, but each value must be unique within the set. The maximum size for a number set is 400 KB.
- Binary Set (BS): This type represents a set of binary values (byte arrays). Each binary set can have multiple binary values, but each value must be unique within the set. The maximum size for a binary set is 400 KB.
- List (L): This type represents a list of attribute values. Lists can contain multiple values of different data types, but the maximum size for a list is 400 KB.
- Map (M): This type represents a collection of attribute name-value pairs. Attribute values can be of any data type, including nested maps and lists. The maximum size for a map is 400 KB.
Our first Item on DynamoDB is inserted.

Programmatically creating Items;
Using Python and Boto3:
Import Boto3 and Initialize DynamoDB Client: Import the Boto3 library and initialize the DynamoDB client.
import boto3 # Initialize DynamoDB client dynamodb = boto3.client('dynamodb')
Creating an Item: Use the put_item method to insert an item into a DynamoDB table.
item = { "productID": { "S": "1" }, "name": { "S": "Example Product" }, "price": { "N": "99.99" } } response = dynamodb.put_item( TableName='Products', Item=item ) print("Item created successfully:", response)
Conclusion:
In this tutorial, we explored the fundamentals of working with Amazon DynamoDB, a fully managed NoSQL database service provided by AWS. DynamoDB offers high scalability, reliability, and low-latency performance, making it an ideal choice for a wide range of applications, from small-scale projects to large-scale enterprise solutions.
We covered various aspects of DynamoDB, including table creation, primary key design, querying data, and inserting items programmatically. Understanding the importance of partition keys and sort keys in table design is crucial for optimizing query performance and distributing workload evenly across partitions.
Continue Reading:
Top Cloud Services providers in Nigeria with CloudPlexo's Innovative Solutions