How to Deploy and use DeepSeek R1 on Amazon Bedrock and Amazon SageMaker
By Moses Daoudu & Victoria Braimoh
on February 13, 2025
.png)
DeepSeek R1 is a cutting-edge AI model family that learns through practice and rewards, similar to human trial-and-error learning. It features an efficient Mixture of Experts (MoE) architecture with 671 billion parameters but only activates 37 billion per task, optimizing performance and cost.
Why Deploy DeepSeek-R1?
The model excels in math and coding, achieving nearly 80% accuracy in advanced math tests and surpassing 96% of human programmers. DeepSeek R1 has two versions: R1-Zero, trained purely through reinforcement learning, and R1, which combines reinforcement learning with example-based training for better explanations. It rivals top models like GPT-4 while being significantly cheaper—27 times less costly than OpenAI’s O1 for token output.
The DeepSeek-R1-Distill Models:
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
For the purpose of this blog post, we will only be deploying the DeepSeek-R1-Distill-Llama-8B, but the same process applies to all distilled DeepSeek-R1 models.
Bedrock Deployment
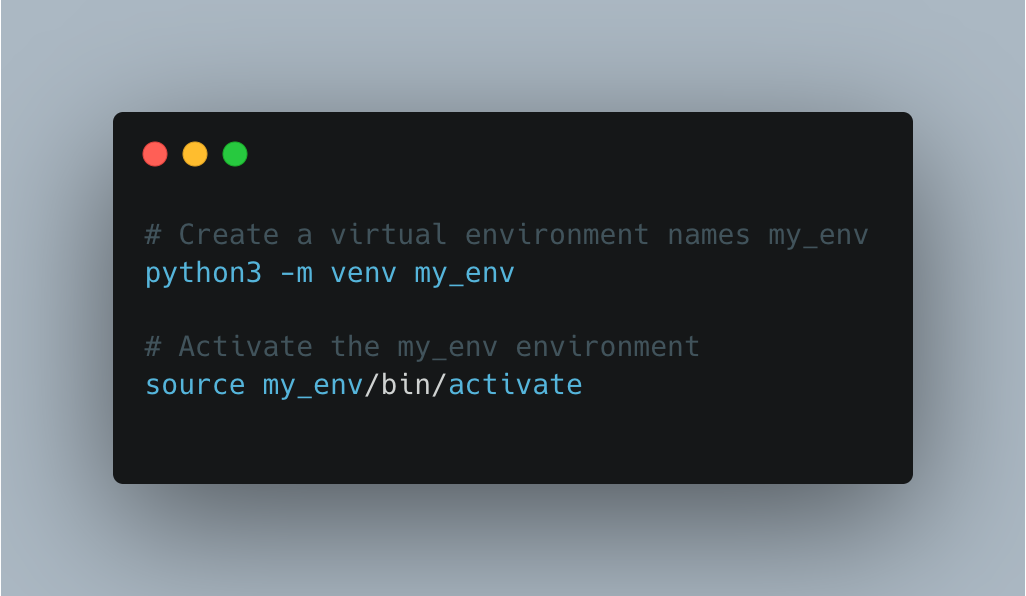
First begin by creating a new virtual environment and initializing it.
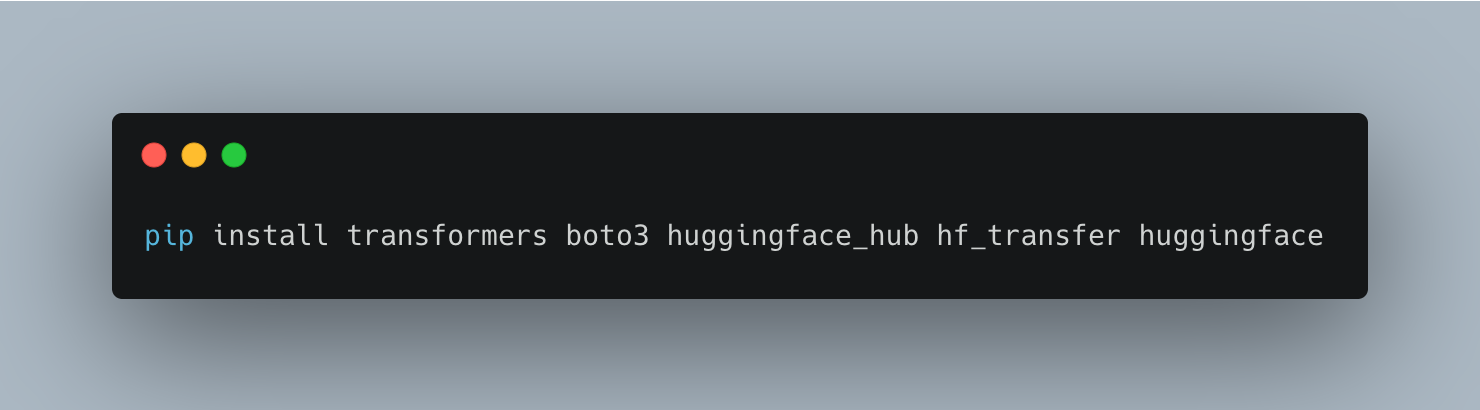
Next we will need to install the python packages that we will be needing such as boto3, transformers and huggingface🤗.
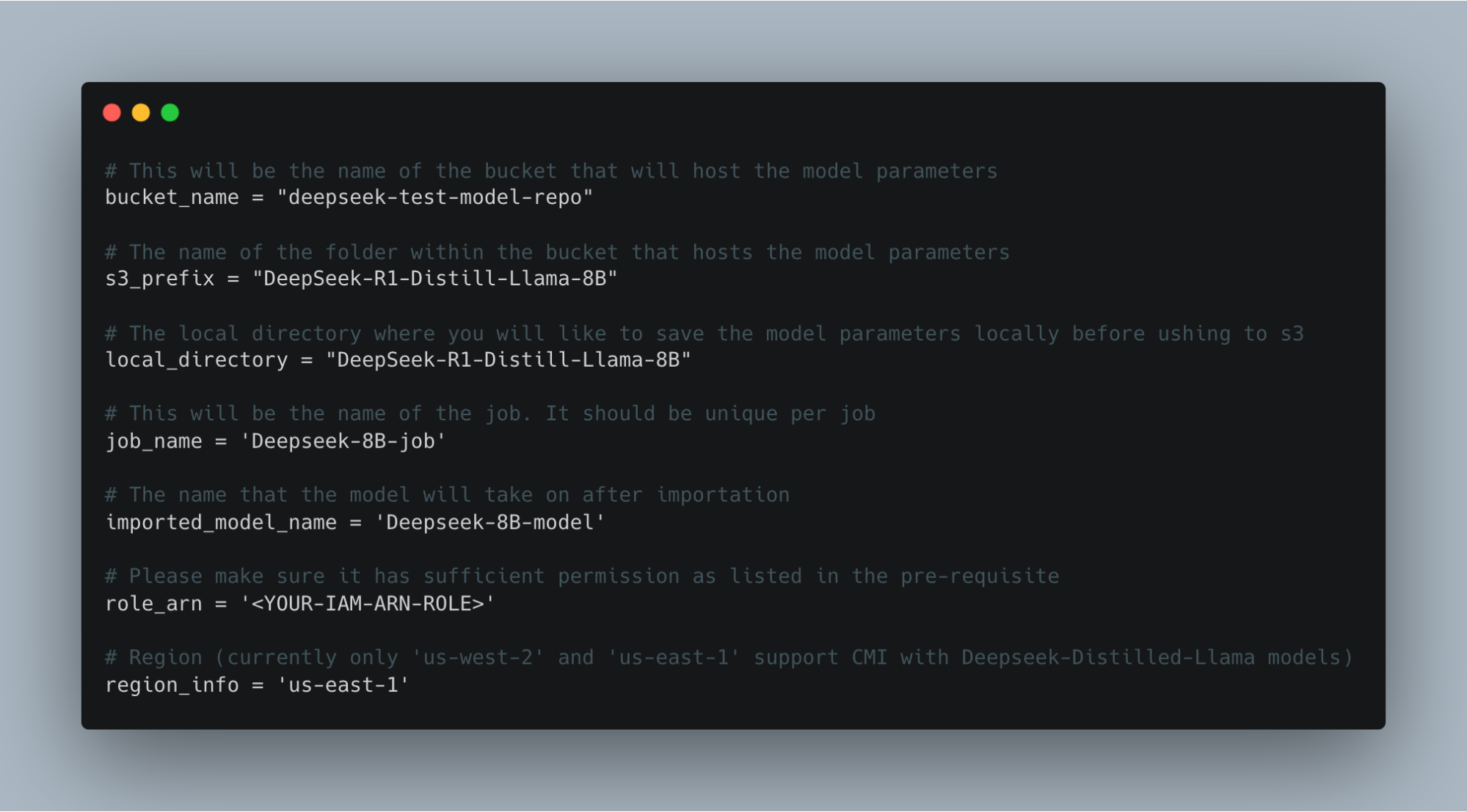
Next up we need to configure the various parameters that we will be needed
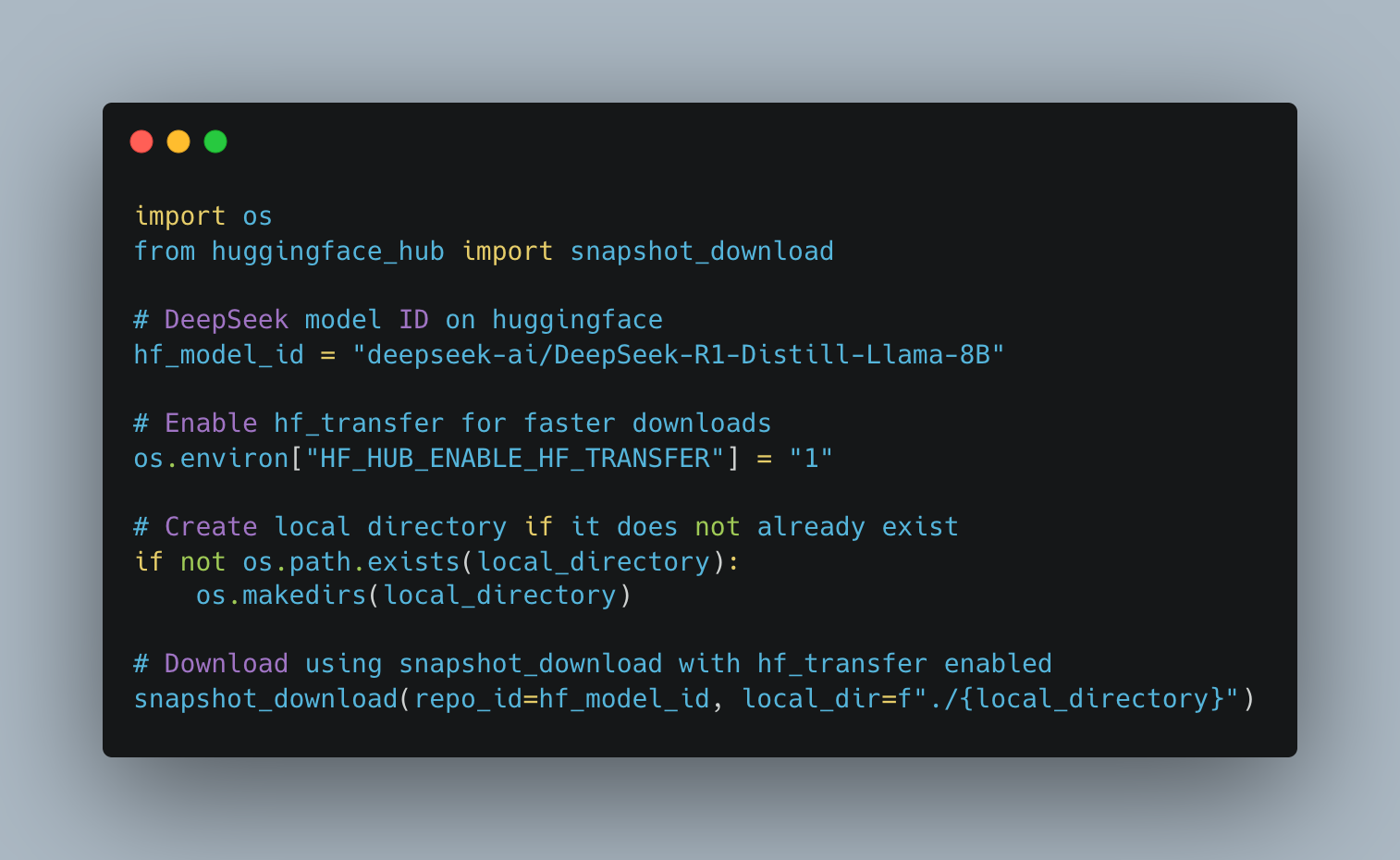
The next step is to download the model weights from huggingface and upload to your s3 bucket. To download the model, make sure that you have at least 15GB to store the 8B parameter model. We recommend that you create an ec2 instance with at least 20GB for this specific operation and delete as soon as the upload to s3 is complete.
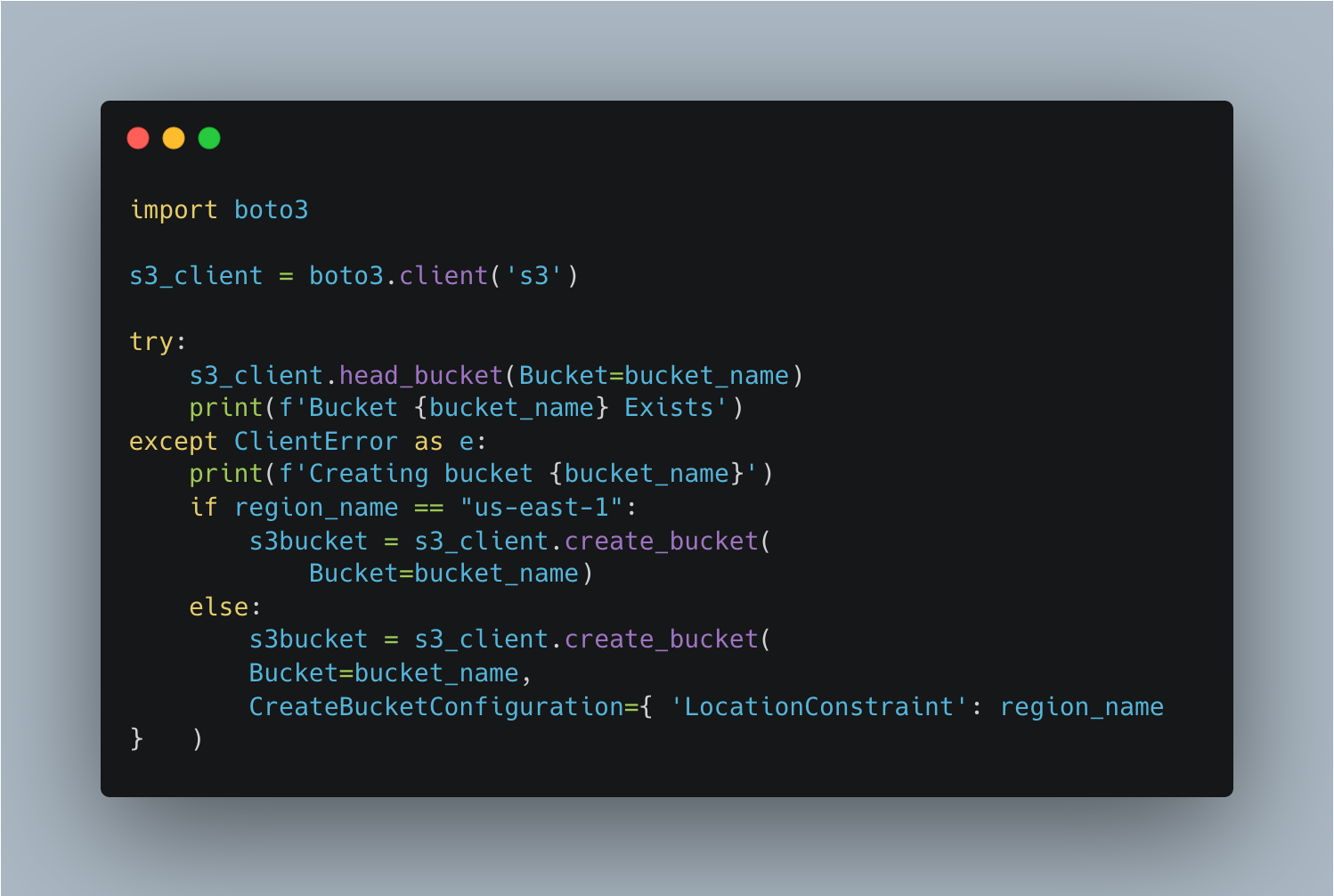
Now we need to create the S3 bucket if it does not already exist
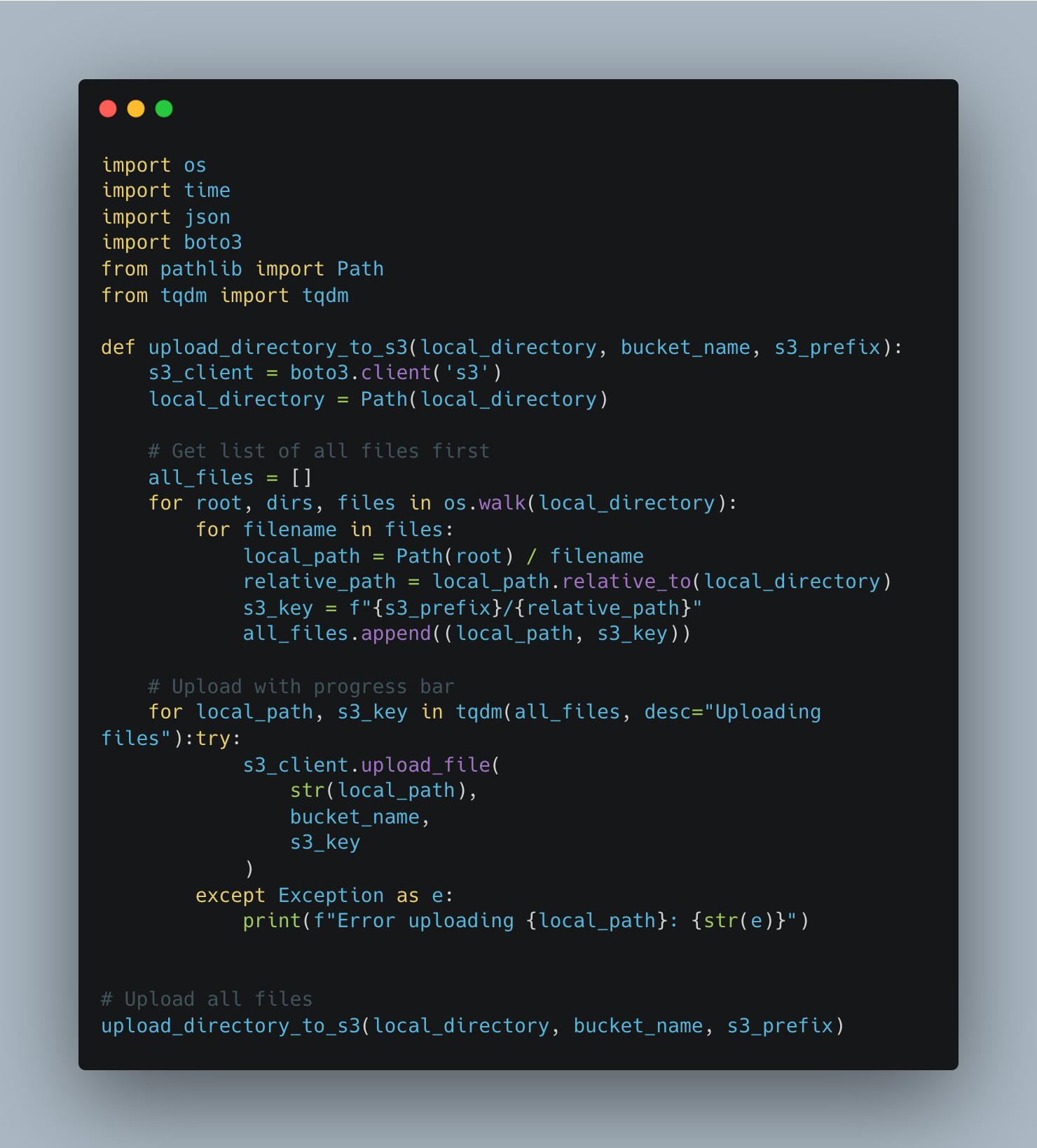
Now we need to upload to our created s3 bucket
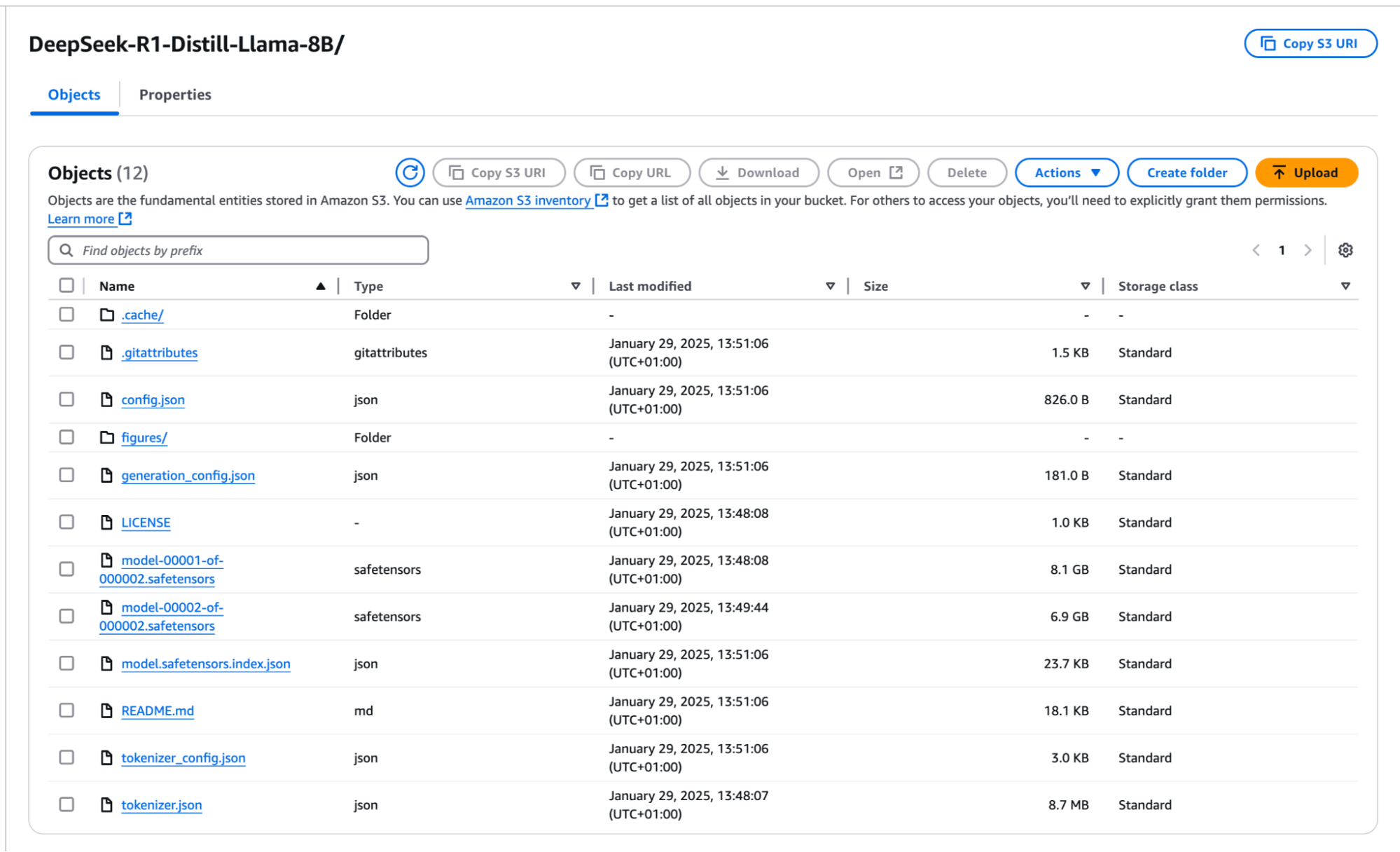
After uploading the model parameters to your s3 bucket, kindly verify from your AWS console to be sure the upload was successful.
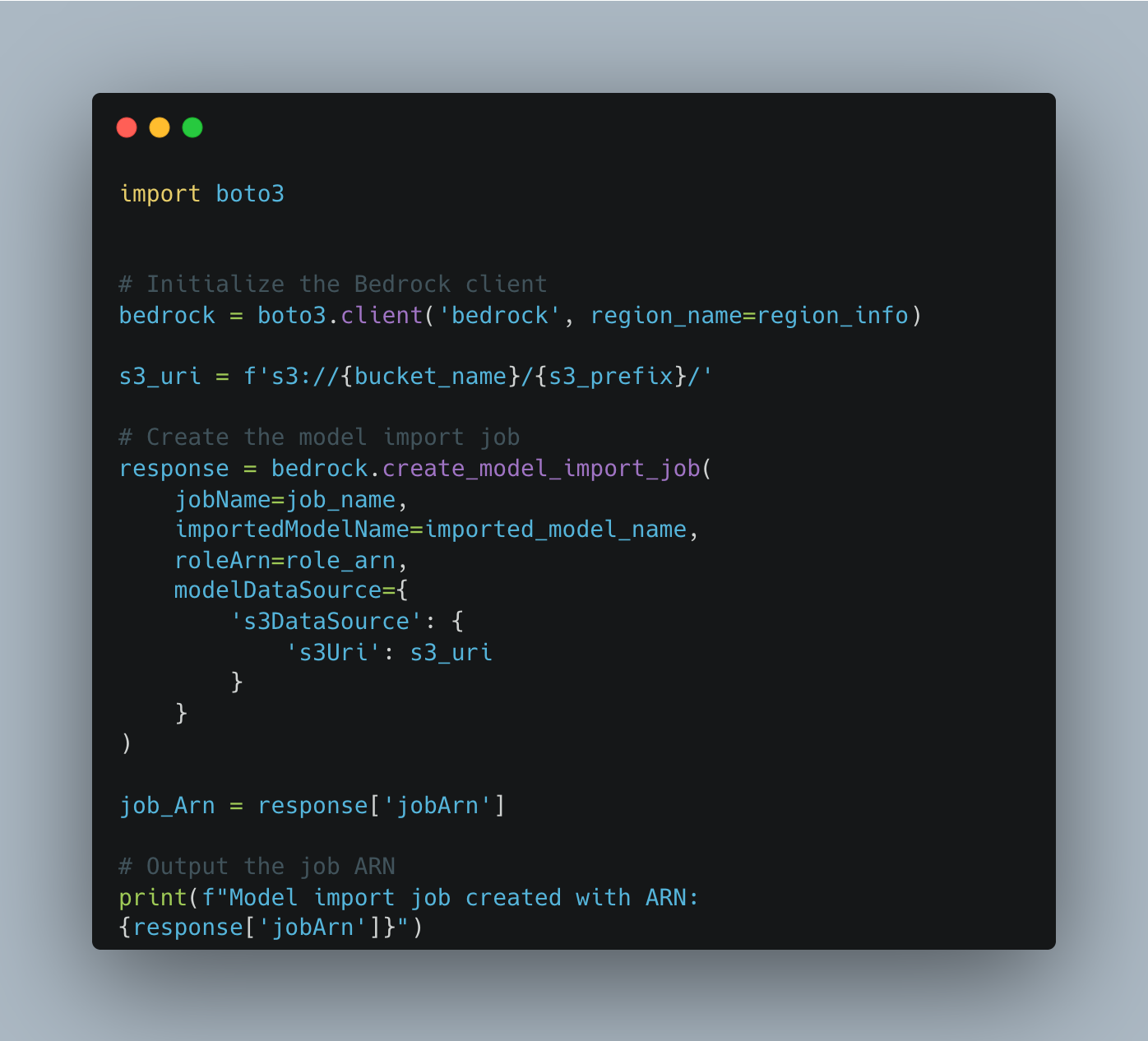
The next step is to create the import job on Amazon Bedrock, please make sure that you have the right permissions in place before doing this operation and you have already set up the IAM role.
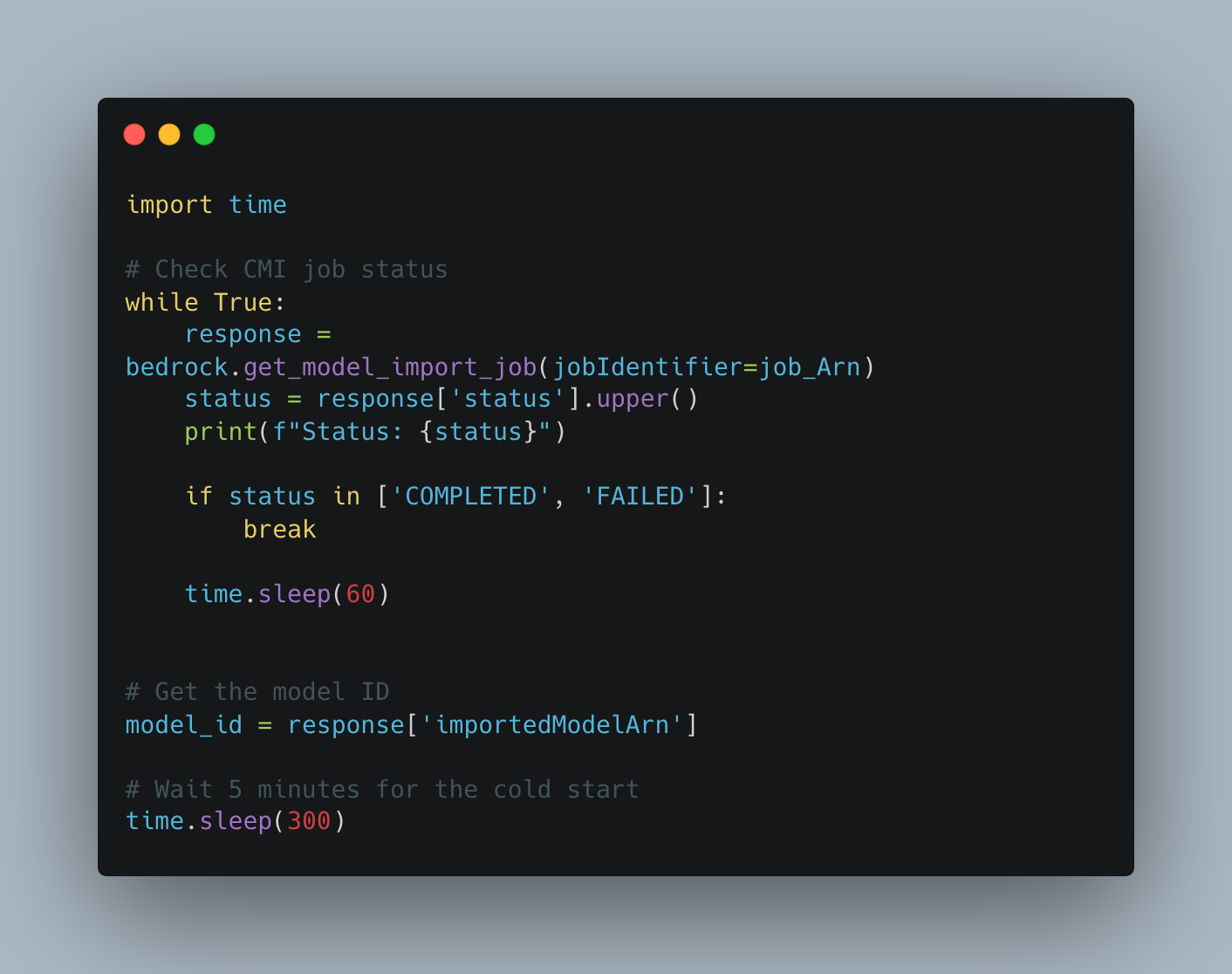
After running the above code, you will need to wait for 6 minutes for the import job to finish, after which you will have to wait an additional 5 minutes cold start. This means that it will take 11 minutes for amazon bedrock to fully import and initialize the model from cold start.
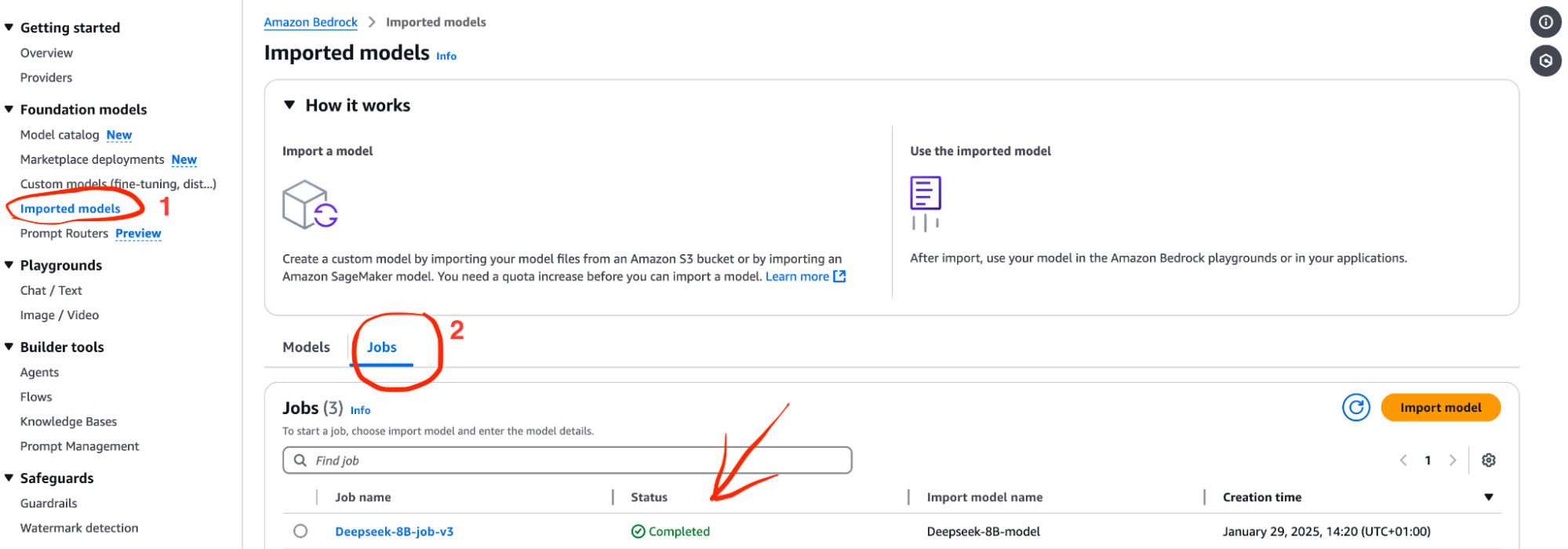
To further verify that your model was imported successfully, kindly check the bedrock imported model sections for the status of your import job. First click on imported models and then finally on the jobs.
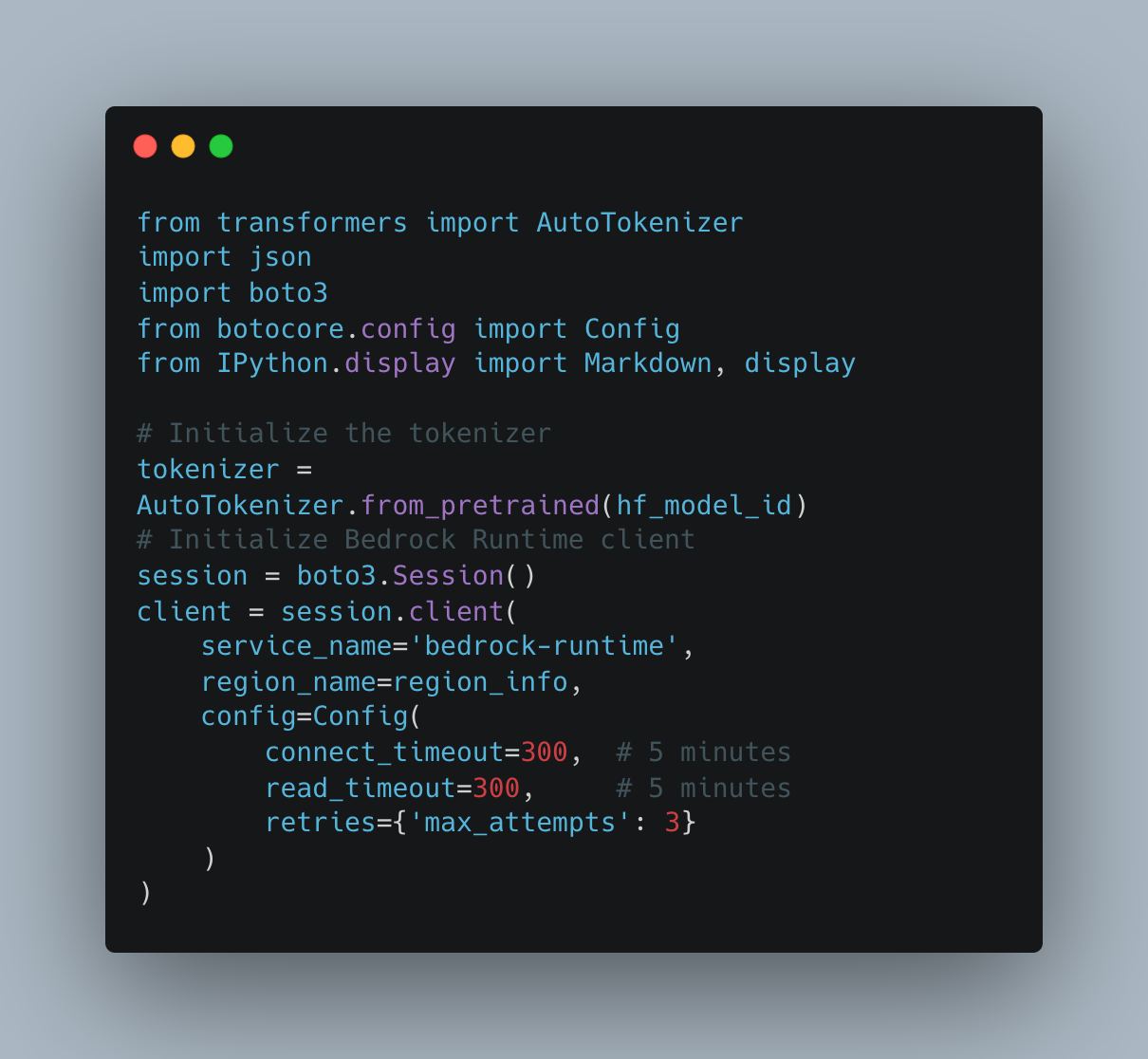
For running inference on the imported model, we need to take care of tokenization of the text for optimal performance. So we first need to use the models’s HuggingFace AutoTokenizer to properly format inputs, then we will create a function to handle the core interaction with the model and then another function to manage longer responses that might exceed token limits.
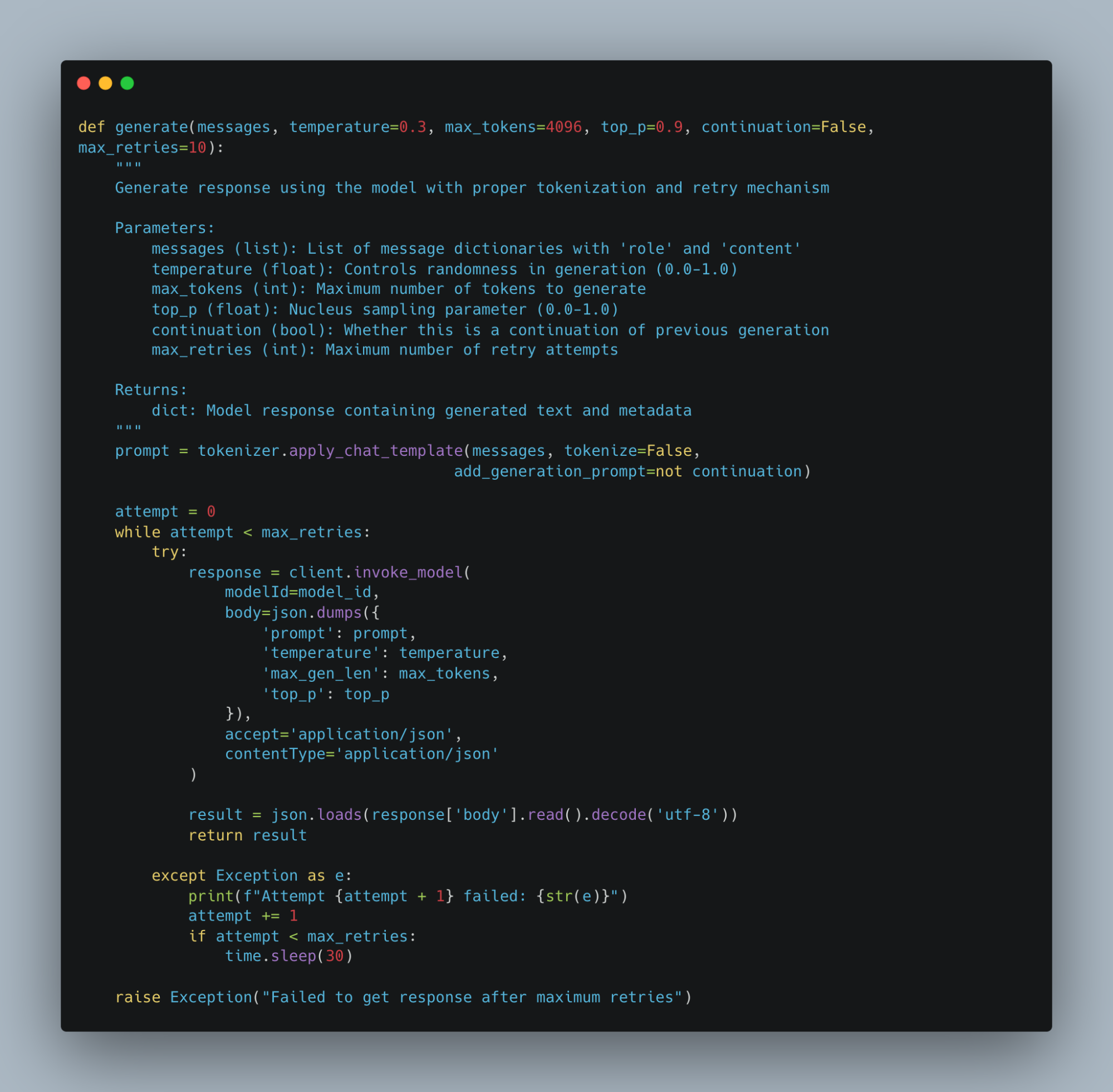
We now need to define the function that handles the basic model interaction with proper tokenization
Now to test the model on a prompt
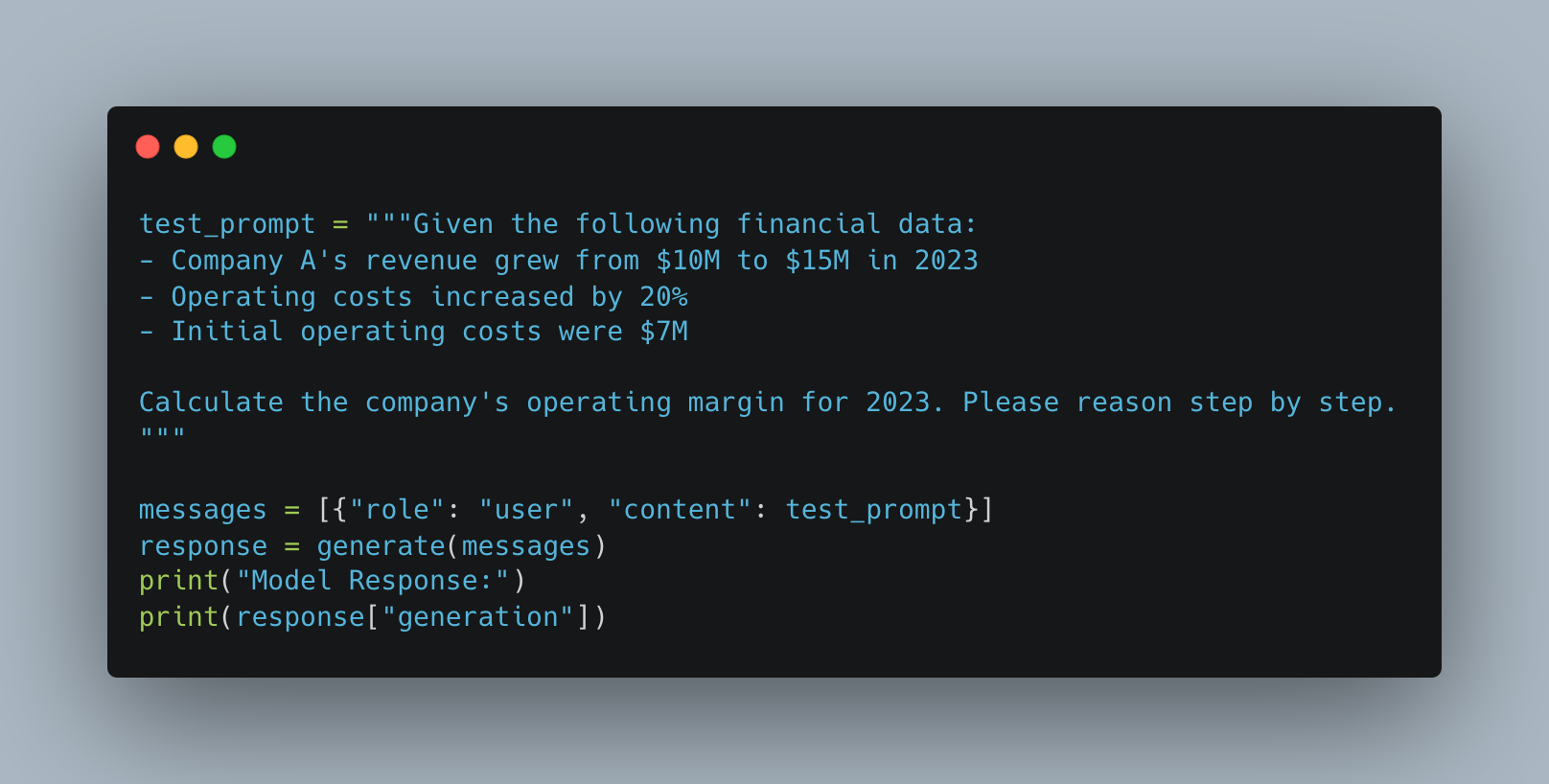
To handle complex reasoning that exceeds the model's output length, we first generate an initial response. If the response is truncated (stop_reason = "length"), we append the partial response to the prompt and make another API call with continuation=True, disabling add_generation_prompt in the tokenizer. This process repeats until a complete response is obtained, ensuring the model's full reasoning process is captured while maintaining coherence. This is shown in the below function
Now to test the model on a complex task:
If you prefer to use the AWS bedrock console for running the model, then follow the below steps
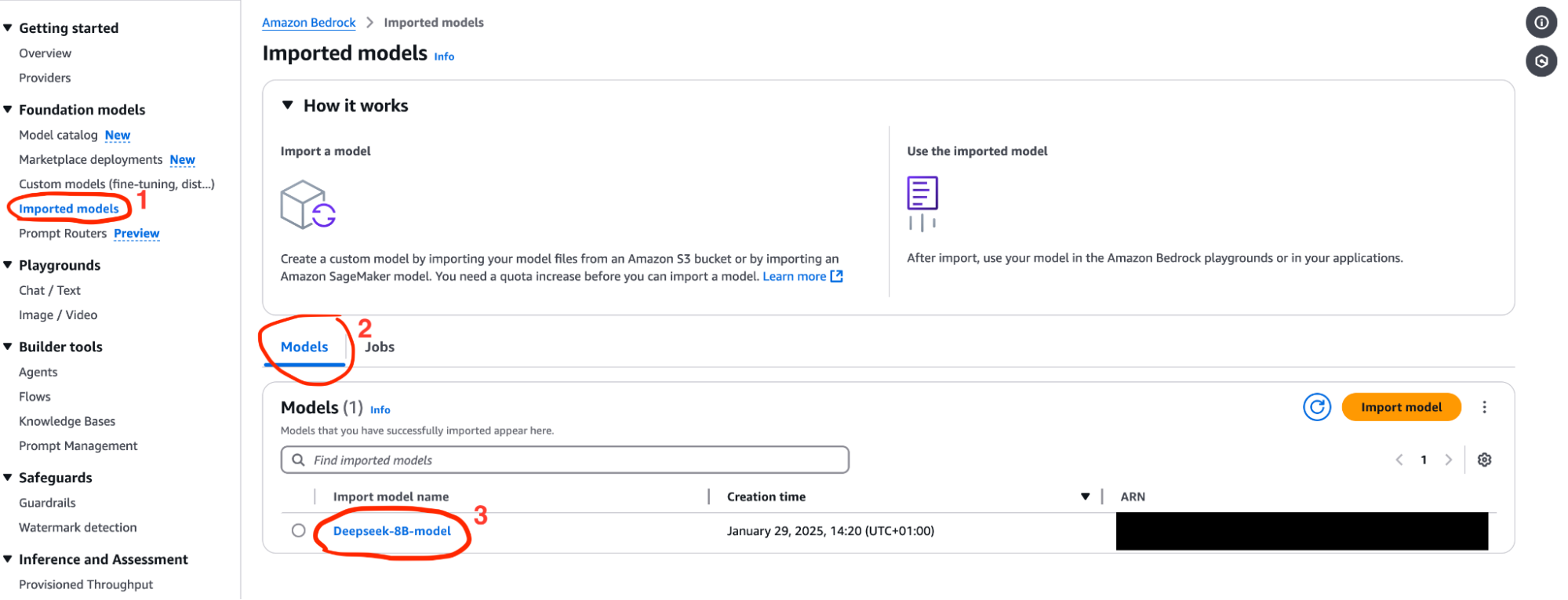
First of all click on the imported model tab on the left side of your screen, then click on the models tab and finally click on the name of the model that you have imported.
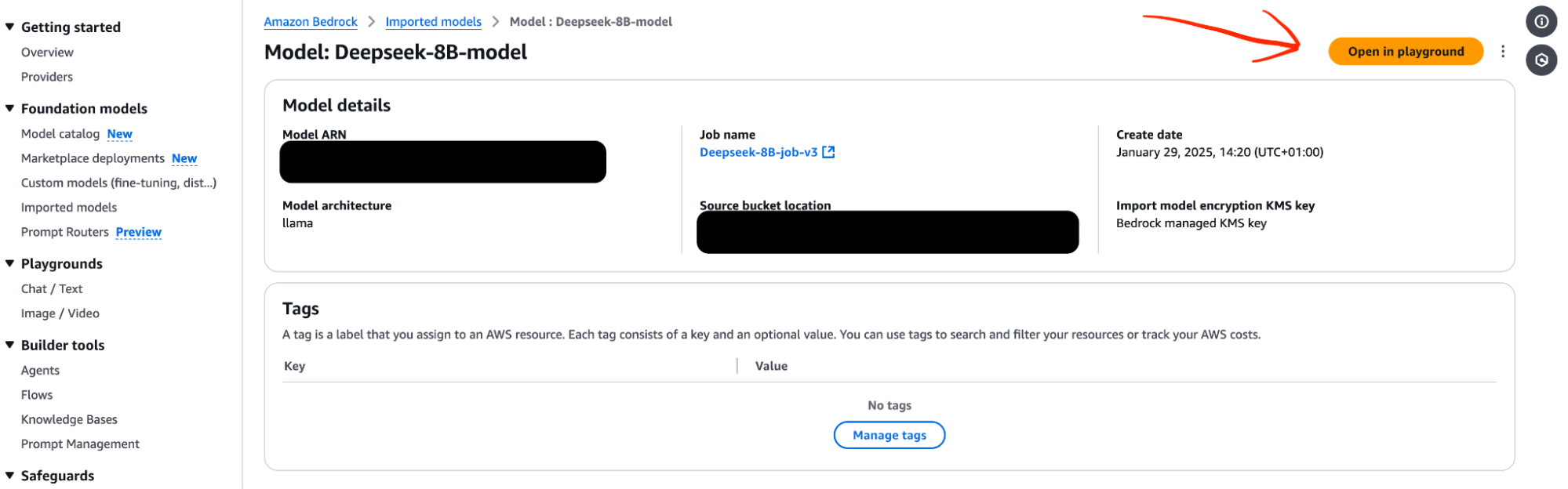
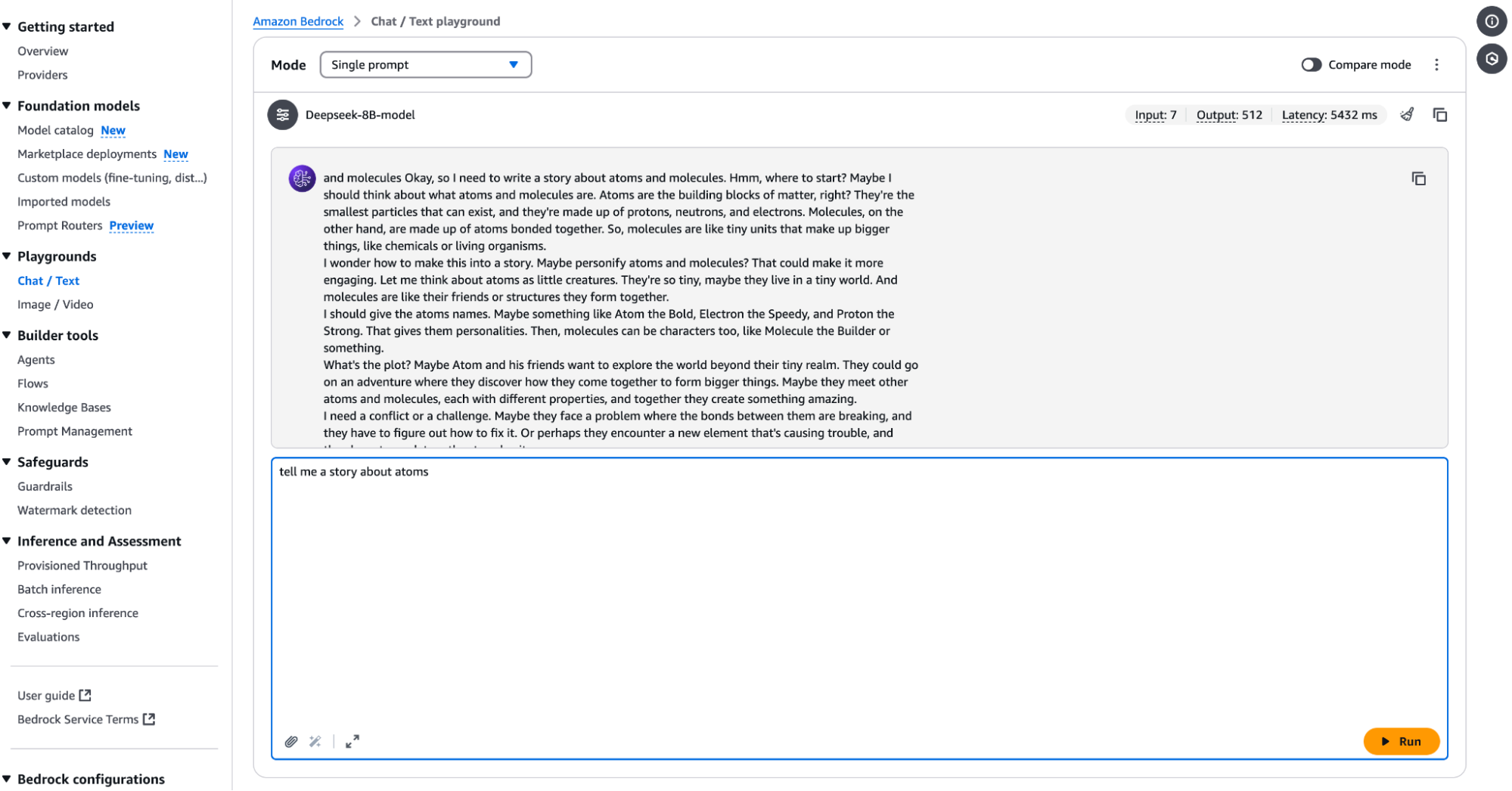
Then click on the Open in Playground tab as shown above, which should take you to another screen where you can test the model.
SageMaker Deployment
Just as we began with bedrock, we will also begin the sagemaker deployment by installing the necessary python based AWS packages within our already created virtual environment.
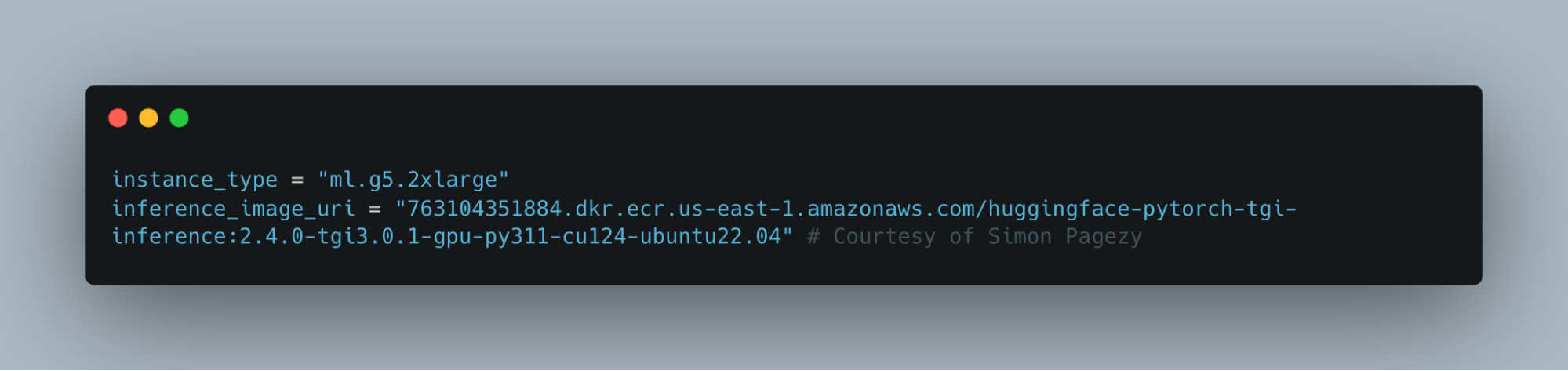
We now need to specify our instance type and inference strategy. Sagemaker supports 2 major forms of inference which are TGI (Text Generation Inference) and LMI (Large Model Inference). For the purpose of this demonstration, we will be sticking with TGI.
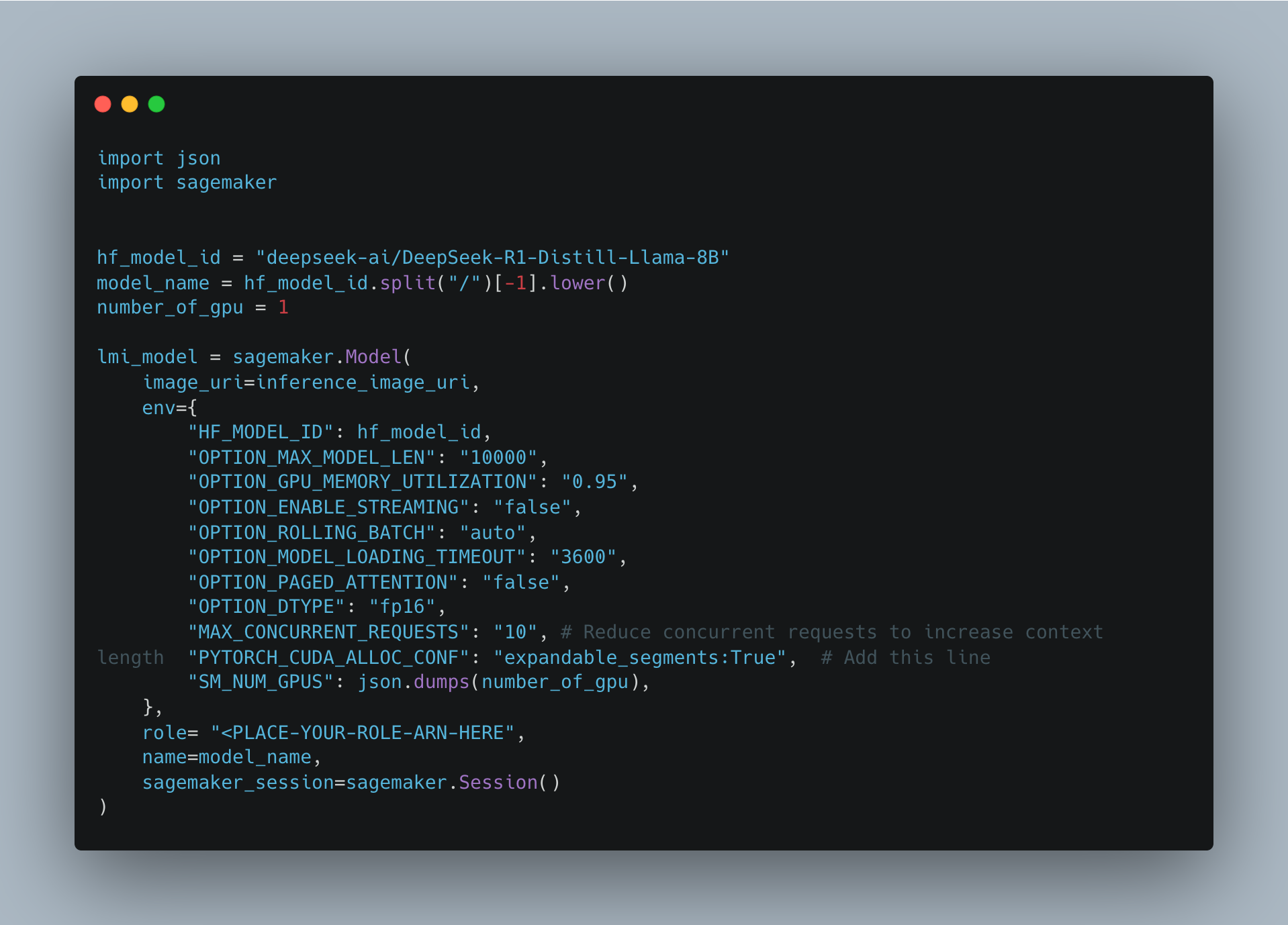
Next we need to set up an Amazon SageMaker model instance using the SageMaker Python SDK to invoke the DeepSeek model for inference. It is important that you already set up the IAM role required for deployment.
Next we need to deploy to a sagemaker endpoint:
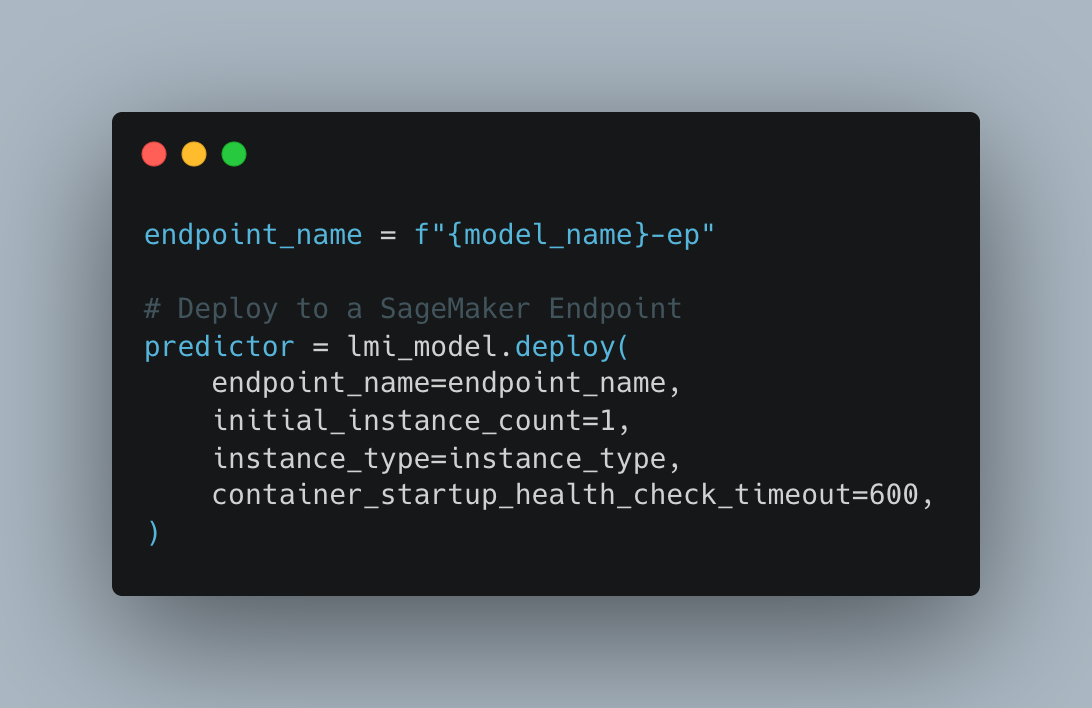
After deploying the model, you can check your amazon sagemaker console to be sure the endpoint deployed successfully.

Once you have verified that your endpoint was deployed successfully and in service, you can then test it out.
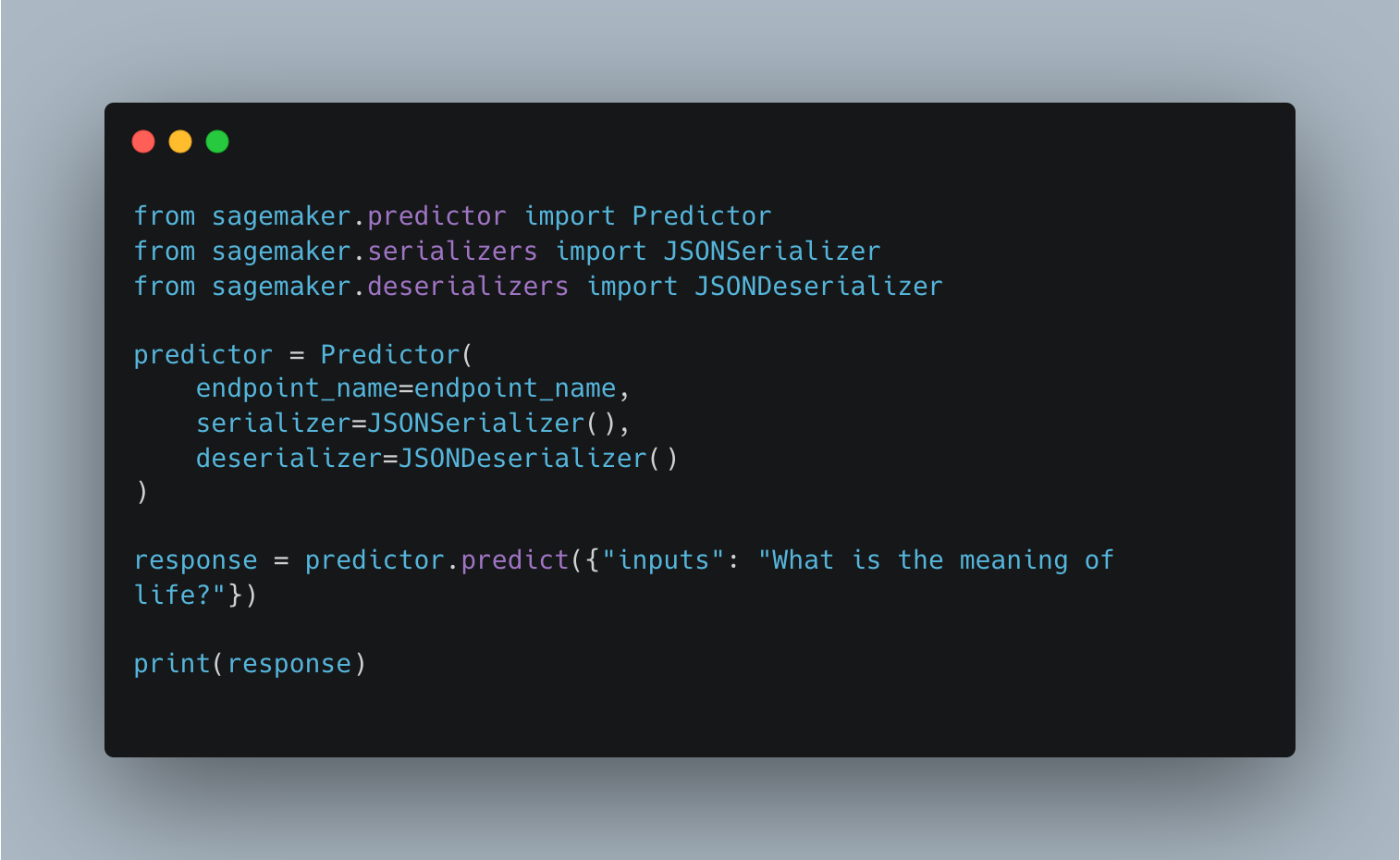
Finally all we need to do is to invoke the created Amazon SageMaker endpoint for inference using the SageMaker Predictor API using the below code
Conclusion
DeepSeek R1's impressive capabilities offer exciting possibilities for AI applications. AWS Bedrock and SageMaker provide the ideal environment for deploying and scaling this powerful model, simplifying everything from fine-tuning to integration.
Whether you're building chatbots or complex AI workflows, the combination of DeepSeek R1 and AWS empowers innovation.
Successfully navigating LLM deployment requires specialized expertise.
CloudPlexo, with our AI/ML focus and advanced AWS certifications, can help you maximize DeepSeek R1's potential. From setup to ongoing optimization, we're ready to accelerate your AI initiatives. Contact us to learn how we can help you build innovative solutions with DeepSeek R1 on AWS.