AWS Comprehend And Its Role In NLP
By abdulmumin yaqeen
on October 3, 2023

Introduction
Imagine if computers could talk with us, understand our words, and even help us make sense of the vast amount of text on the internet. Well, that's exactly what Natural Language Processing (NLP) does.
But before we dive into the exciting world of NLP, let's break it down a bit. NLP helps computers understand and work with human languages, like English or any other language we speak. It's what makes chatbots chat and helps us search the web more effectively.
Now, NLP wouldn't be as cool without text processing. Think of text processing as the toolbox for NLP. It's where we break down sentences into words, figure out what's important, and clean up messy text.
And speaking of cool tools, there's AWS Comprehend. It's like the superhero of NLP tools, especially in the cloud. AWS Comprehend can do things like figure out if a sentence is happy or sad, find important names in text, and even understand different languages.
So, in this article, we're going to take you on a journey. We'll start by exploring what NLP is all about, then we'll peek into the world of text processing, and finally, we'll introduce you to AWS Comprehend and how it's like NLP's best friend, helping us unlock the secrets hidden within the words we use every day.
NLP enables computers to perform tasks like:
- Text Understanding: It helps computers read and comprehend text documents, articles, or messages, allowing them to extract useful information or answer questions.
- Language Translation: NLP is behind the magic of translation apps, turning text from one language into another so people all around the world can communicate.
- Chatbots and Virtual Assistants: Those helpful bots you chat with online or voice assistants like Siri and Alexa? They use NLP to understand your questions and provide answers.
- Sentiment Analysis: NLP can figure out if a piece of text sounds happy, sad, or neutral. This is used for things like analyzing customer reviews or social media sentiment.
- Information Retrieval: It helps search engines like Google find the most relevant web pages when you type in a question.
In short, NLP is about bridging the gap between humans and computers through language. It's a bit like teaching computers to speak our language, making them more helpful, efficient, and capable of understanding the vast amount of text information available today.
Text Processing
Text processing lies at the heart of Natural Language Processing (NLP), a field of artificial intelligence that deals with the interaction between computers and human language. In the digital age, where vast amounts of text data are generated daily through social media, websites, emails, and more, the need for effective text-processing techniques has never been greater. Text processing in NLP encompasses a wide range of tasks and techniques, each crucial for understanding, extracting meaning, and making sense of human language. In this article, we will delve into the foundations of text processing in NLP, exploring its fundamental components and highlighting its significance in various applications.
Tokenization: Breaking Language into Units
At the very core of text processing in NLP is tokenization. Tokenization is the process of breaking down a text into smaller units, typically words or subword units like subtokens or characters. This step is pivotal as it transforms unstructured text data into a format that can be understood and processed by machines. Consider the sentence: "The quick brown fox jumps over the lazy dog." Tokenizing this sentence would result in the following units: ["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."].
Tokenization is not merely about splitting words; it also involves handling punctuation, special characters, and language-specific complexities. For instance, languages like German often have compound words that need to be correctly segmented to preserve their meaning. Robust tokenization is essential for downstream NLP tasks like sentiment analysis, named entity recognition, and machine translation.
Stopword Removal: Eliminating Noise
After tokenization, the next step in text processing often involves the removal of stopwords. Stopwords are common words such as "the," "and," "in," and "is" that appear frequently in a language but usually carry little semantic information. Removing stopwords helps reduce noise in the text data and focuses on the more meaningful words, making subsequent NLP tasks more efficient.
However, the choice of which words to consider as stopwords can vary based on the application. In sentiment analysis, for instance, stopwords may carry valuable sentiment-related information, so they might not be removed. The task at hand and the goals of the analysis influence the decision regarding stopword removal.
Stemming and Lemmatization: Normalizing Words
Languages often exhibit morphological variations, where words change their form based on tense, number, gender, or other linguistic factors. Stemming and lemmatization are techniques used to normalize words by reducing them to their root or base form.
Stemming involves removing suffixes and prefixes to find the word's root. For instance, "jumping" becomes "jump," and "swimming" becomes "swim." While stemming is more aggressive in its reductions, it can sometimes result in non-words or incorrect representations.
Lemmatization, on the other hand, involves reducing words to their dictionary form, called a lemma. For example, "better" becomes "good," and "mice" becomes "mouse." Lemmatization generally provides more accurate and meaningful representations but can be computationally more expensive.
Choosing between stemming and lemmatization depends on the specific NLP task and the trade-off between precision and efficiency.
Part-of-Speech Tagging: Understanding Word Roles
Understanding the grammatical roles of words in a sentence is crucial for many NLP tasks. Part-of-speech tagging assigns a label to each word in a sentence, indicating whether it's a noun, verb, adjective, adverb, etc. This information is valuable for tasks like syntactic parsing, information extraction, and machine translation.
For instance, in the sentence "The cat sleeps peacefully," part-of-speech tagging would label "The" as a determiner, "cat" as a noun, "sleeps" as a verb, and "peacefully" as an adverb. This knowledge allows NLP models to understand sentence structure and word relationships.
Named Entity Recognition: Identifying Entities
Named Entity Recognition (NER) is a text-processing task that focuses on identifying and categorizing named entities in text, such as names of people, organizations, locations, dates, and more. NER is essential for information extraction, question answering, and entity linking.
For example, in the sentence "Apple Inc. was founded by Steve Jobs in Cupertino, California in 1976," NER would recognize "Apple Inc." as an organization, "Steve Jobs" as a person, and "Cupertino, California" as a location.
NER models use contextual information and language patterns to identify these entities, and their accuracy is critical for applications like document summarization and knowledge graph construction.
In Conclusion, Text processing forms the bedrock of Natural Language Processing, enabling machines to understand, analyze, and generate human language. Tokenization, stopword removal, stemming, lemmatization, part-of-speech tagging, and named entity recognition are just a few of the essential techniques in this multifaceted field. As NLP continues to advance, text processing will remain an integral part, unlocking new possibilities in fields ranging from chatbots and sentiment analysis to machine translation and information retrieval. Understanding these foundational concepts is key to harnessing the power of NLP for various real-world applications.
AWS Comprehend
Amazon Web Services (AWS) Comprehend is a powerful cloud-based Natural Language Processing (NLP) service designed to extract valuable insights and information from text data. NLP, a branch of artificial intelligence, focuses on making sense of human language by analyzing and understanding text. AWS Comprehend offers a wide range of features and capabilities that empower organizations to unlock the hidden potential within their textual data. In this article, we'll explore the key features of AWS Comprehend and its role in NLP applications.
Key Features of AWS Comprehend
- Text Classification:
AWS Comprehend allows you to automatically classify text documents into predefined categories or custom labels. This feature is invaluable for organizing and categorizing large volumes of textual data, such as customer reviews, support tickets, or news articles. It enables businesses to quickly identify trends and sentiments within their text data. - Sentiment Analysis:
Sentiment analysis is a critical component of NLP, and AWS Comprehend excels in this area. It can determine the sentiment (positive, negative, or neutral) expressed in a piece of text. This capability is immensely useful for gauging customer sentiment in product reviews, social media posts, or surveys, helping businesses make data-driven decisions. - Named Entity Recognition (NER):
NER is the process of identifying and categorizing entities within text, such as names of people, organizations, dates, and locations. AWS Comprehend's NER feature is essential for extracting structured information from unstructured text data, enabling tasks like entity linking, information retrieval, and content indexing. - Entity Recognition for Custom Models:
While AWS Comprehend provides pre-trained models for NER, it also allows you to train custom models for entity recognition. This is particularly valuable when working with industry-specific terminology or unique entities relevant to your organization. - Topic Modeling:
AWS Comprehend can identify and extract topics from a collection of documents, making it easier to organize and navigate large text corpora. This is especially useful in content recommendation systems and document summarization. - Language Detection:
Language detection is crucial when working with multilingual data. AWS Comprehend can automatically detect the language of a text document, enabling organizations to process and analyze text data in multiple languages seamlessly. - Syntax Analysis:
AWS Comprehend can perform syntactic analysis, providing information about sentence boundaries and grammatical structures. This feature is beneficial for tasks like parsing and understanding the grammatical structure of sentences.
AWS Comprehend's Role in NLP
AWS Comprehend plays a pivotal role in NLP applications across various industries. Here's how it contributes to the field:
- Efficient Data Processing:
AWS Comprehend simplifies the preprocessing of textual data, handling tasks like tokenization, stopword removal, and lemmatization. This allows NLP practitioners to focus on higher-level tasks, such as modeling and analysis. - Sentiment Analysis and Customer Insights:
Businesses can leverage Comprehend's sentiment analysis to gain a deeper understanding of customer sentiment, helping them tailor their products, services, and marketing strategies accordingly. - Information Extraction and Knowledge Graphs:
The named entity recognition capabilities of AWS Comprehend are instrumental in building knowledge graphs and extracting structured information from unstructured text. This can be applied in various domains, including healthcare, finance, and legal. - Multilingual Support:
In a globalized world, the ability to work with text data in multiple languages is essential. AWS Comprehend's language detection and multilingual support make it a valuable tool for international businesses. - Customization for Domain-Specific NLP:
With the ability to train custom NER models, AWS Comprehend can be tailored to suit the specific needs of industries with specialized terminologies, such as pharmaceuticals or legal.
Implementation
We will take a peak into the implementation of some of these features of AWS comprehend very quickly, most of it is just an API call and some basic formatting of the result, so there is no complex algorithm you need to understand or worry about writing some machine learning stuff.
But before we jump to it, I would like to make this easier for us by providing all the text data we will be using for the various tests in a single file, so we can just import them.
Also, you will need to have an AWS account, install and configure the AWS CLI for this to work, if you don't already have one.
Test data
text = """ Amazon, based in Seattle, Washington, is one of the largest and most well-known technology companies in the world. Founded by Jeff Bezos in 1994, the company initially started as an online bookstore before expanding into various other product categories, including electronics, cloud computing, artificial intelligence, and entertainment. Amazon Web Services (AWS) is a subsidiary of Amazon providing on-demand cloud computing platforms and APIs to individuals, companies, and governments, on a metered pay-as-you-go basis. AWS offers a wide range of services, including computing power, storage, database services, machine learning, and analytics. The company's logo features a smile-shaped arrow that goes from the letter 'A' to 'Z', symbolizing the idea that Amazon has everything a customer could need. Amazon has revolutionized the way people shop, changing the traditional brick-and-mortar retail landscape and fostering the growth of e-commerce. In recent years, Amazon has also ventured into producing its own original content for its streaming platform, Amazon Prime Video, competing with other streaming giants like Netflix and Hulu. Overall, Amazon has had a significant impact on the world of technology, e-commerce, and entertainment, and its innovations continue to influence various industries. """ text_positive = """ I just wanted to say that your customer service team is fantastic! They were incredibly helpful and resolved my issue in no time. Thank you for the excellent support! """ text_negative = """ I'm extremely disappointed with my recent purchase. The item was damaged when it arrived, and it took forever to get a response from your support team. This experience was frustrating and unacceptable. """ text_feedback = """ I'm writing to express my frustration with your company's recent service. My name is Emily Johnson, and my customer ID is 987654321. On July 15th, I made a purchase of $1000 on your website using my credit card ending in **** **** **** 1234. The order was for a product that was marked as in-stock, but it has not been delivered to my address at 789 Elm Street, Apartment 4C, Anytown, USA, as promised. This delay has caused a great deal of inconvenience, and I would appreciate a prompt resolution to this issue. """ text_feedback1 = """ John Smith's email address is john.smith@example.com, and he lives at 456 Oak Street, Apartment 3B, Springfield, USA. His social security number is 123-45-6789. """ text_feedback2 = """ Dear Customer, We regret to inform you of an issue with your recent purchase. Our records show that John Smith, with the email address john.smith@example.com and phone number +1 (555) 123-4567, made a purchase of $500 on March 25, 2023, using his credit card with the number **** **** **** 5678 and an expiration date of 12/25. The billing address associated with this transaction is 123 Maple Avenue, Apartment 2D, Springfield, USA. However, it appears there was a problem with the delivery to this address. The package containing your order, tracking number 987654321, was reported as delivered on March 28, but you have informed us that you did not receive it. We sincerely apologize for this inconvenience and are taking immediate steps to investigate this issue. Our priority is to ensure that you receive the product you ordered promptly. Please expect a follow-up call from our customer service representative, Emily Johnson, who can be reached at emily.johnson@example.com or +1 (555) 987-6543. Emily is dedicated to resolving this matter to your satisfaction. We value your business and are committed to providing the best possible customer experience. If you have any additional concerns or questions, please don't hesitate to contact us. Thank you for your understanding and patience. Sincerely, AWS Team """
Sentiment Analysis Implementation
This is one of the really powerful domains in NLP because this can greatly help businesses, and organizations make better decisions, let's say based on the sentiment around the user feedback they are getting.
The code below is the implementation of sentiment analysis with AWS Comprehend API using Python.
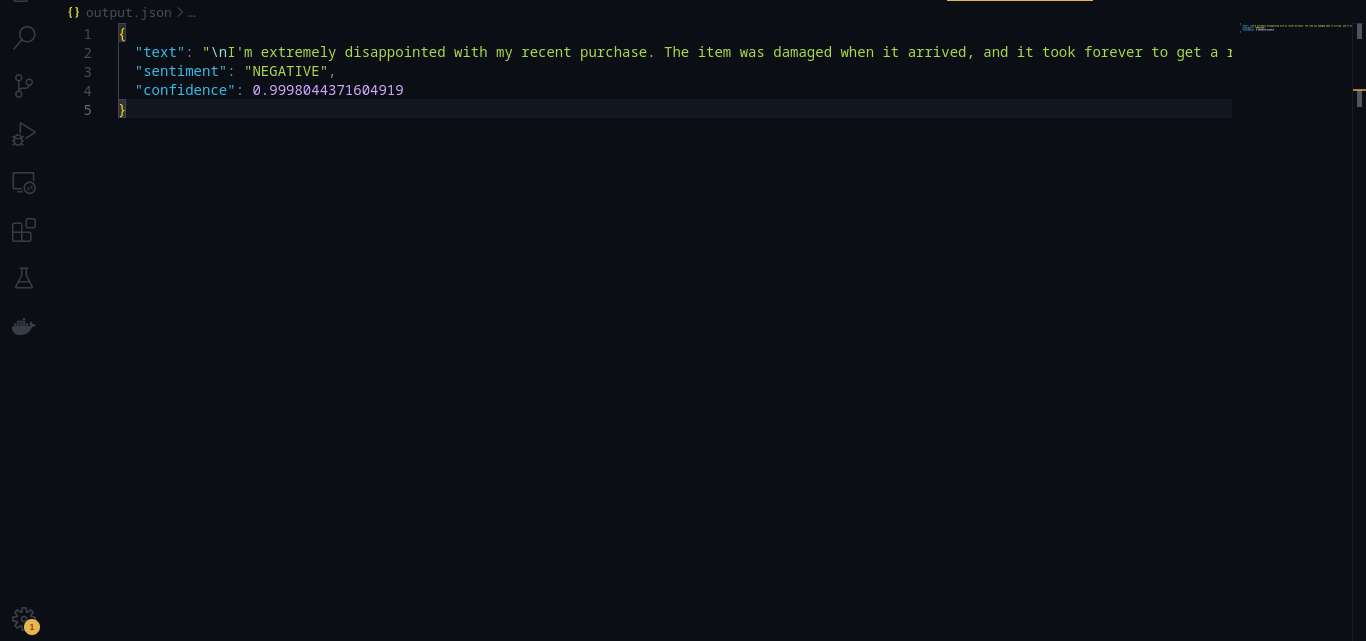
import boto3 from text_input import text, text_negative, text_positive import pprint import json def detect_sentiment(): # create sesssion session = boto3.Session() # initialize aws comprehend comprehend = session.client('comprehend') sentiment_response = comprehend.detect_sentiment( Text=text_negative, LanguageCode="en") sentiment = sentiment_response['Sentiment'] confidence = sentiment_response['SentimentScore'][sentiment.capitalize()] pprint.pprint(sentiment_response) return { "text": text_negative, "sentiment": sentiment, "confidence": confidence } result = detect_sentiment() with open('output.json', 'w') as file: json.dump(result, file, indent=2)
This is a very straightforward and powerful piece of code. In Just a few lines, we can detect the sentiment of any kind of text, and works well with other languages as well.
The output of the following code, based on our test data will look something like this:
Named Entity Recognition Implementation
Another really interesting area in NLP and AWS comprehend feature, This can detect entities like names, locations, products, and more from plain text.
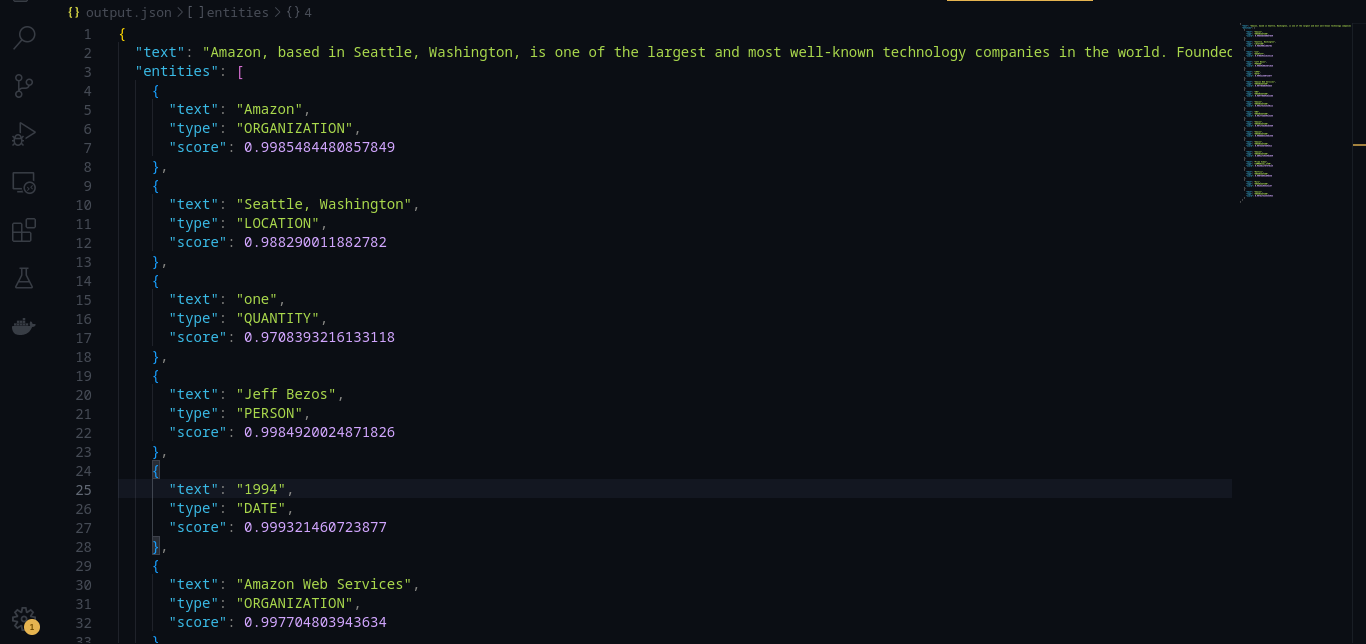
import boto3 from text_input import text import json import pprint def detect_entities(): # Create a Boto3 session session = boto3.Session() # Initialize the Comprehend client using the session comprehend = session.client('comprehend') # Perform entity recognition entity_response = comprehend.detect_entities(Text=text, LanguageCode='en') # Extract entities entities = entity_response['Entities'] pprint.pprint(entities) # Prepare the response entity_list = [] for entity in entities: entity_data = { "text": entity['Text'], "type": entity['Type'], "score": entity['Score'] } entity_list.append(entity_data) response = { "text": text, "entities": entity_list } return response result = detect_entities() with open('output.json', 'w') as file: json.dump(result, file, indent=2)
This is not very different from the previous code, just that the API we're calling is different, and of course, will need a different formatting.
Overall, the result is really amazing and we're able to get cool entities out of this text.
PII (Personally Identifiable Information )
One more cool thing I will share is PIL(personally identifiable information), this one can be very interesting, especially in customer support. This can bring out personal information of the sender that he/she includes in the message/text or mail.
Here is the code for that:
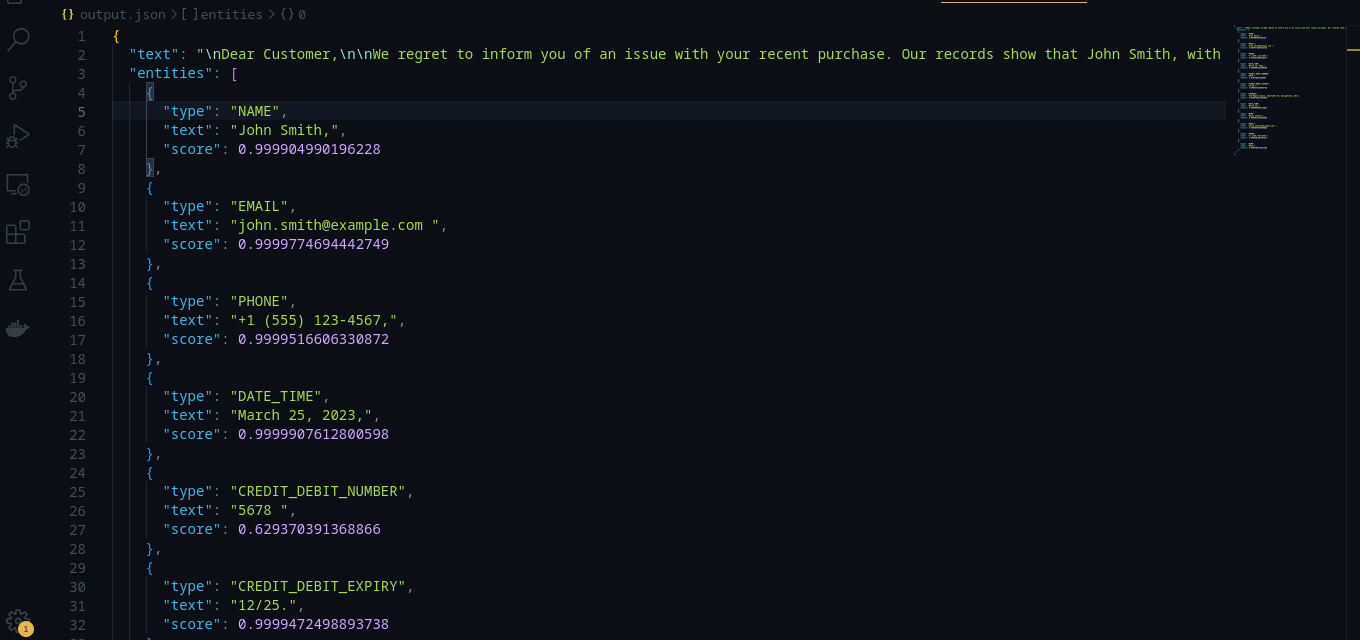
import boto3 from text_input import text_feedback2 import json import pprint def getString(text, begin, end): return text[begin:end+1] def detect_entities(): # Create a Boto3 session session = boto3.Session() # Initialize the Comprehend client using the session comprehend = session.client('comprehend') # Perform PII recognition entity_response = comprehend.detect_pii_entities( Text=text_feedback2, LanguageCode='en') pprint.pprint(entity_response) # Extract entities entities = entity_response['Entities'] pprint.pprint(entities) # Prepare the response entity_list = [] for entity in entities: entity_data = { "type": entity['Type'], "text": getString(text_feedback2, entity["BeginOffset"], entity["EndOffset"]), "score": entity['Score'] } entity_list.append(entity_data) response = { "text": text_feedback2, "entities": entity_list } return response result = detect_entities() with open('output.json', 'w') as file: json.dump(result, file, indent=2)
In this, we included a little function to get the detected text because the api only returns the offset.
The output of the code will look like this:
Summary
In a rapidly evolving digital landscape, Natural Language Processing (NLP) stands as the bridge between human language and computing. NLP empowers computers to understand, interpret, and interact with the language we use every day. It unlocks a world of possibilities, from translating languages and analyzing sentiments to powering chatbots and making sense of the vast sea of text data on the internet.
And with AWS comprehend, you can easily build a cost-effective solution and ship fast to your end users.