FinOps 2.0: A Guide to Governing AI & Cloud Spend in 2026
By David Ewele
on January 20, 2026

FinOps 2.0: A Guide to Governing AI & Cloud Spend in 2026
In 2023, the cloud bill conversation was dominated by reserved instances and storage tiers. By 2026, the landscape has shifted entirely. The primary driver of cloud cost is no longer just keeping the lights on; it is inference.
We are seeing a trend across the industry often described as "Inference Bill Shock." As GenAI moves from experimental pilots to production workflows, every new feature carries an implicit "AI tax." The challenge is that traditional cloud cost management advice, like shutting down idle EC2 instances, is insufficient for probabilistic AI models that charge by the token rather than the hour.
To maintain healthy margins in this new era, mature organizations must graduate from standard Cloud Cost Management to GenAI FinOps. This isn't just about saving money. It is about engineering efficiency and ensuring your AI innovation is sustainable.
Here are the five strategic shifts required to master AI unit economics in 2026.
1. Aggressive Model Right-Sizing
The most common financial mistake in AI architecture is paying "PhD prices for elementary school tasks."
Early adopters often defaulted to massive foundation models for every interaction. While these models offer incredible reasoning capabilities, using them for simple tasks like sentiment analysis or summarization is financial inefficiency at its peak.
The Strategy:
- Tier Your Models: Reserve your massive parameters for complex, multi-step reasoning tasks that require high nuance.
- Embrace "Distilled" Models: For high-volume, low-complexity tasks, switch to Small Language Models (SLMs) or distilled versions. These models are significantly more cost-effective and faster, often delivering indistinguishable quality for routine operations.
Real-World Scenario: The "Helpdesk" Trap
The Context: An internal IT Helpdesk bot handles 50,000 queries a month.
The Mistake: The engineering team hooks the bot up to a flagship, massive-parameter model (e.g., GPT-5 class). Every time an employee asks, "How do I reset my password?", it costs the company $0.04 in inference compute because the model is "thinking" too hard about a simple answer.
The Fix: You implement an "Intent Routing" layer. The system detects that "Password Reset" is a routine intent and routes the query to a micro-model or a static script. The cost drops to $0.0001 per interaction. Multiplied by 50,000 queries, this is a massive margin recovery without affecting the user experience.
2. Operationalize "AI Unit Economics"
You cannot optimize what you cannot measure on a unit basis. A $50,000 monthly AI bill is acceptable if it generates $500,000 in value. It becomes a governance failure if it only generates $50,000.
The shift here is moving away from tracking "Total Monthly Spend" to understanding your Cost of Goods Sold (COGS) per feature.
The Strategy:
- The Golden Metric: Track "Cost per Token" and "Cost per Successful Interaction." This granularity exposes which features are draining margin.
- Strict Tagging: Implement rigorous tagging strategies to map specific AI features (e.g., "Customer Support Bot") directly to revenue streams.
- Note on Observability: This level of granularity often requires advanced observability. Tools like Wendu can help correlate these performance metrics with cost, ensuring you have visibility into the efficiency of your AI workloads, not just their uptime.

Real-World Scenario: The "Unlimited" Feature
The Context: A SaaS platform launches an "AI Executive Summary" button for their dashboard.
The Mistake: The finance team sees the AWS bill explode but can't tell which customer tier is driving it. It turns out, "Basic Tier" users (who pay very little) are spamming the button, effectively costing the company more in compute than they pay in subscription fees.
The Fix: By tracking COGS per interaction, you realize the feature costs $0.15 per use. You adjust the product packaging so "Basic" users get 5 summaries/month, while "Enterprise" users get unlimited. You have successfully aligned cost with revenue.
3. Migrate to Specialized Silicon
In the early days of the AI boom, organizations grabbed whatever GPU capacity they could find. In 2026, relying on generic, previous-generation GPUs for pure inference is often overkill.
The Strategy:
- Adopt "Inferentia" Class Chips: Move production inference workloads to specialized hardware like AWS Inferentia2 or Trainium. These chips are architected specifically to lower the cost-per-inference, often reducing costs by up to 50% compared to general-purpose GPUs without sacrificing throughput.
Real-World Scenario: The "Training" Hardware Waste
The Context: A logistics company built their model on Nvidia H100s because that's what their data scientists used for training.
The Mistake: They pushed that same hardware configuration to production. They are now paying a premium for "training capabilities" (like massive gradient calculations) that aren't needed when the model is simply answering questions (inference).
The Fix: They migrate the inference endpoint to AWS Inf2 instances. The model performs just as fast, but the hourly compute cost drops by 40%, instantly improving the application's profitability.
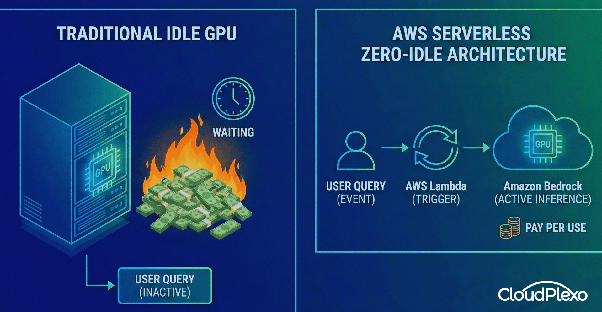
4. Serverless AI Architectures
Paying for a GPU to sit idle while waiting for a user query is a massive source of waste. In a "Day 2" operations environment, idle resources are the enemy of efficiency.
The Strategy:
- Scale-to-Zero: Leverage provisioned concurrency intelligently or adopt purely event-driven architectures.
- The "Zero Idle" Policy: Utilize services like AWS Lambda to trigger inference on Amazon Bedrock only when needed. This ensures you pay only when the model is actively processing, effectively eliminating costs during low-traffic periods.
Real-World Scenario: The "Zombie" GPU
The Context: A document processing app runs a dedicated GPU instance 24/7 to handle uploaded PDFs.
The Mistake: Traffic drops to near zero between 11 PM and 6 AM. Yet, the dedicated instance is running and billing the full hourly rate just "listening" for a file that isn't coming.
The Fix: The team shifts to a Serverless architecture using Amazon Bedrock. Now, they pay only when a PDF is actually uploaded and processed. The bill for the 11 PM to 6 AM window drops to effectively zero.
5. Engineering Accountability (Shift Cost Left)
Finance teams cannot fix inefficient code. By the time the bill arrives, the money is already spent. The responsibility must shift left to the engineering teams building the features.
The Strategy:
- Pre-Deployment Estimates: Integrate tooling into your CI/CD pipeline that flags cost anomalies. If a Pull Request switches to a model that is 10x more expensive, the engineer should be alerted immediately.
- Gamification: Create visibility for teams regarding their "Performance-to-Cost" ratio. When engineers see the price tag before merging code, architectural decisions become more disciplined.
CASE STUDY: How CloudPlexo Helped Ibile Bank Modernize & Optimize their Cloud Infrastructure on AWS
Real-World Scenario: The Expensive Library Update
The Context: A developer updates a library that changes the default model in an API wrapper from gpt-4o-mini to gpt-4-turbo.
The Mistake: The code functions perfectly, so it passes all unit tests. It is deployed to production. Three days later, the daily burn rate jumps 10x.
The Fix: A "FinOps Gate" in the CI/CD pipeline analyzes the configuration change. It flags the PR with a warning: "⚠️ Projected Cost Increase: +900%. Approval required from Engineering Lead." The disaster is caught before it ever reaches production.
Conclusion
FinOps 2.0 is less about budget cuts and more about architectural discipline. As AI features become ubiquitous, companies that ignore AI unit economics risk seeing their margins eroded by API costs.
The goal is to ensure that as your usage scales, your revenue scales faster than your infrastructure bill.
Ready to audit your AI spend?
Pick one high-volume AI feature this week and calculate its true Unit Cost. The result might surprise you. If you need help building a governance framework that scales with your ambition, let's talk.